This journal utilises an Online Peer Review Service (OPRS) for submissions. By clicking "Continue" you will be taken to our partner site https://mc.manuscriptcentral.com/apjournals. Please be aware that your Cambridge account is not valid for this OPRS and registration is required. We strongly advise you to read all "Author instructions" in the "Journal information" area prior to submitting.
We prove new results about comparing the efficiency of general state space Markov chain Monte Carlo algorithms that randomly select a possibly different reversible method at each step (previously known only for finite state spaces). We also provide new, simpler, more accessible proofs of key results, and analyse numerous examples. We provide a full proof of the formula for the asymptotic variance for real-valued functionals on 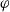 $\varphi$-irreducible reversible Markov chains, first introduced by Kipnis and Varadhan (1986, Commun. Math. Phys. 104, 1–19). Given two Markov kernels P and Q with stationary measure
$\varphi$-irreducible reversible Markov chains, first introduced by Kipnis and Varadhan (1986, Commun. Math. Phys. 104, 1–19). Given two Markov kernels P and Q with stationary measure 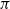 $\pi$, we say that the Markov kernel P efficiency-dominates the Markov kernel Q if the asymptotic variance with respect to P is at most the asymptotic variance with respect to Q for every real-valued functional
$\pi$, we say that the Markov kernel P efficiency-dominates the Markov kernel Q if the asymptotic variance with respect to P is at most the asymptotic variance with respect to Q for every real-valued functional 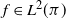 $f\in L^2(\pi)$. Assuming only a basic background in functional analysis, we prove that for two reversible Markov kernels P and Q, P efficiency-dominates Q if and only if the operator
$f\in L^2(\pi)$. Assuming only a basic background in functional analysis, we prove that for two reversible Markov kernels P and Q, P efficiency-dominates Q if and only if the operator 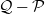 $\mathcal{Q}-\mathcal{P}$, where
$\mathcal{Q}-\mathcal{P}$, where 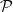 $\mathcal{P}$ is the operator on
$\mathcal{P}$ is the operator on 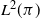 $L^2(\pi)$ that maps
$L^2(\pi)$ that maps 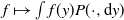 $f\mapsto\int f(y)P(\cdot,\mathrm{d}y)$ and similarly for
$f\mapsto\int f(y)P(\cdot,\mathrm{d}y)$ and similarly for 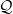 $\mathcal{Q}$, is positive on
$\mathcal{Q}$, is positive on 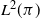 $L^2(\pi)$, i.e.
$L^2(\pi)$, i.e.  $\langle f,\left(\mathcal{Q}-\mathcal{P}\right)f\rangle\geq0$ for every
$\langle f,\left(\mathcal{Q}-\mathcal{P}\right)f\rangle\geq0$ for every 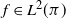 $f\in L^2(\pi)$ (previous proofs for general state spaces use technical results from monotone operator function theory). We use this result to show that under mild conditions, sandwich variants of data augmentation algorithms efficiency-dominate the original algorithm. We also provide other easy-to-check sufficient conditions for efficiency dominance, some of which are generalized from the finite state space case. We also provide a proof based on that of Tierney (1998, Ann. Appl. Prob. 8, 1–9) that Peskun dominance is a sufficient condition for efficiency dominance for reversible kernels. Using these results, we show that Markov kernels formed by random selection of other ‘component’ Markov kernels will always efficiency-dominate another Markov kernel formed in this way, as long as the component kernels of the former efficiency-dominate those of the latter. These results on the efficiency dominance of combining component kernels generalizes the results on the efficiency dominance of combined chains introduced by Neal and Rosenthal (2024, J. Appl. Prob. 62, 188–208) from finite state spaces to general state spaces.
$f\in L^2(\pi)$ (previous proofs for general state spaces use technical results from monotone operator function theory). We use this result to show that under mild conditions, sandwich variants of data augmentation algorithms efficiency-dominate the original algorithm. We also provide other easy-to-check sufficient conditions for efficiency dominance, some of which are generalized from the finite state space case. We also provide a proof based on that of Tierney (1998, Ann. Appl. Prob. 8, 1–9) that Peskun dominance is a sufficient condition for efficiency dominance for reversible kernels. Using these results, we show that Markov kernels formed by random selection of other ‘component’ Markov kernels will always efficiency-dominate another Markov kernel formed in this way, as long as the component kernels of the former efficiency-dominate those of the latter. These results on the efficiency dominance of combining component kernels generalizes the results on the efficiency dominance of combined chains introduced by Neal and Rosenthal (2024, J. Appl. Prob. 62, 188–208) from finite state spaces to general state spaces.
In this paper we are concerned with susceptible–infected–removed (SIR) epidemics with vertex-dependent recovery and infection rates on complete graphs. We show that the hydrodynamic limit of our model is driven by a nonlinear function-valued ordinary differential equation consistent with a mean-field analysis. We further show that the fluctuation of our process is driven by a generalized Ornstein–Uhlenbeck process. A key step in the proofs of the main results is to show that states of different vertices are approximately independent as the population  $N\rightarrow+\infty$.
$N\rightarrow+\infty$.
We study stationary distributions in the context of stochastic reaction networks. In particular, we are interested in complex balanced reaction networks and the reduction of such networks by assuming that a set of species (called non-interacting species) are degraded fast (and therefore essentially absent from the network), implying that some reaction rates are large relative to others. Technically, we assume that these reaction rates are scaled by a common parameter N and let  $N\to\infty$. The limiting stationary distribution as
$N\to\infty$. The limiting stationary distribution as  $N\to\infty$ is compared with the stationary distribution of the reduced reaction network obtained by elimination of the non-interacting species. In general, the limiting stationary distribution could differ from the stationary distribution of the reduced reaction network. We identify various sufficient conditions under which these two distributions are the same, including when the reaction network is detailed balanced and when the set of non-interacting species consists of intermediate species. In the latter case, the limiting stationary distribution essentially retains the form of the complex balanced distribution. This finding is particularly surprising given that the reduced reaction network could be non-weakly reversible and might exhibit unconventional kinetics.
$N\to\infty$ is compared with the stationary distribution of the reduced reaction network obtained by elimination of the non-interacting species. In general, the limiting stationary distribution could differ from the stationary distribution of the reduced reaction network. We identify various sufficient conditions under which these two distributions are the same, including when the reaction network is detailed balanced and when the set of non-interacting species consists of intermediate species. In the latter case, the limiting stationary distribution essentially retains the form of the complex balanced distribution. This finding is particularly surprising given that the reduced reaction network could be non-weakly reversible and might exhibit unconventional kinetics.
We study a continuous-time mutually catalytic branching model on the  $\mathbb{Z}^{d}$. The model describes the behavior of two different populations of particles, performing random walk on the lattice in the presence of branching, that is, each particle dies at a certain rate and is replaced by a random number of offspring. The branching rate of a particle in one population is proportional to the number of particles of another population at the same site. We study the long time behavior for this model, in particular, coexistence and noncoexistence of two populations in the long run. Finally, we construct a sequence of renormalized processes and use duality techniques to investigate its limiting behavior.
$\mathbb{Z}^{d}$. The model describes the behavior of two different populations of particles, performing random walk on the lattice in the presence of branching, that is, each particle dies at a certain rate and is replaced by a random number of offspring. The branching rate of a particle in one population is proportional to the number of particles of another population at the same site. We study the long time behavior for this model, in particular, coexistence and noncoexistence of two populations in the long run. Finally, we construct a sequence of renormalized processes and use duality techniques to investigate its limiting behavior.
We describe the asymptotic behaviour of large degrees in random hyperbolic graphs for all values of the curvature parameter  $\alpha$. We prove that, with high probability, the node degrees satisfy the following ordering property: the ranking of the nodes by decreasing degree coincides with the ranking of the nodes by increasing distance to the centre, at least up to any constant rank. In the sparse regime
$\alpha$. We prove that, with high probability, the node degrees satisfy the following ordering property: the ranking of the nodes by decreasing degree coincides with the ranking of the nodes by increasing distance to the centre, at least up to any constant rank. In the sparse regime  $\alpha>\tfrac{1}{2}$, the rank at which these two rankings cease to coincide is
$\alpha>\tfrac{1}{2}$, the rank at which these two rankings cease to coincide is  $n^{1/(1+8\alpha)+o(1)}$. We also provide a quantitative description of the large degrees by proving the convergence in distribution of the normalised degree process towards a Poisson point process. In particular, this establishes the convergence in distribution of the normalised maximum degree of the graph. A transition occurs at
$n^{1/(1+8\alpha)+o(1)}$. We also provide a quantitative description of the large degrees by proving the convergence in distribution of the normalised degree process towards a Poisson point process. In particular, this establishes the convergence in distribution of the normalised maximum degree of the graph. A transition occurs at  $\alpha = \tfrac{1}{2}$, which corresponds to the connectivity threshold of the model. For
$\alpha = \tfrac{1}{2}$, which corresponds to the connectivity threshold of the model. For  $\alpha < \tfrac{1}{2}$, the maximum degree is of order
$\alpha < \tfrac{1}{2}$, the maximum degree is of order  $n - O(n^{\alpha + 1/2})$, whereas for
$n - O(n^{\alpha + 1/2})$, whereas for  $\alpha \geq \tfrac{1}{2}$, the maximum degree is of order
$\alpha \geq \tfrac{1}{2}$, the maximum degree is of order  $n^{1/(2\alpha)}$. In the
$n^{1/(2\alpha)}$. In the  $\alpha < \tfrac{1}{2}$ and
$\alpha < \tfrac{1}{2}$ and  $\alpha > \tfrac{1}{2}$ cases, the limit distribution of the maximum degree belongs to the class of extreme value distributions (Weibull for
$\alpha > \tfrac{1}{2}$ cases, the limit distribution of the maximum degree belongs to the class of extreme value distributions (Weibull for  $\alpha < \tfrac{1}{2}$ and Fréchet for
$\alpha < \tfrac{1}{2}$ and Fréchet for  $\alpha > \tfrac{1}{2}$). This refines previous estimates on the maximum degree for
$\alpha > \tfrac{1}{2}$). This refines previous estimates on the maximum degree for  $\alpha > \tfrac{1}{2}$ and extends the study of large degrees to the dense regime
$\alpha > \tfrac{1}{2}$ and extends the study of large degrees to the dense regime  $\alpha \leq \tfrac{1}{2}$.
$\alpha \leq \tfrac{1}{2}$.
We derive the exact asymptotics of  $\mathbb{P} {\{\sup\nolimits_{\boldsymbol{t}\in {\mathcal{A}}}X(\boldsymbol{t})>u \}} \textrm{ as}\ u\to\infty,$ for a centered Gaussian field
$\mathbb{P} {\{\sup\nolimits_{\boldsymbol{t}\in {\mathcal{A}}}X(\boldsymbol{t})>u \}} \textrm{ as}\ u\to\infty,$ for a centered Gaussian field  $X({\boldsymbol{t}}),\ {\boldsymbol{t}}\in \mathcal{A}\subset\mathbb{R}^n$,
$X({\boldsymbol{t}}),\ {\boldsymbol{t}}\in \mathcal{A}\subset\mathbb{R}^n$,  $n>1$ with continuous sample paths almost surely, for which
$n>1$ with continuous sample paths almost surely, for which  $\arg \max_{\boldsymbol{t}\in {\mathcal{A}}} {\mathrm{Var}}(X(\boldsymbol{t}))$ is a Jordan set with a finite and positive Lebesgue measure of dimension
$\arg \max_{\boldsymbol{t}\in {\mathcal{A}}} {\mathrm{Var}}(X(\boldsymbol{t}))$ is a Jordan set with a finite and positive Lebesgue measure of dimension  $k\le n$ and its dependence structure is not necessarily locally stationary. Our findings are applied to derive the asymptotics of tail probabilities related to performance tables and chi processes, particularly when the covariance structure is not locally stationary.
$k\le n$ and its dependence structure is not necessarily locally stationary. Our findings are applied to derive the asymptotics of tail probabilities related to performance tables and chi processes, particularly when the covariance structure is not locally stationary.
In this paper we study one-sided hypothesis testing under random sampling without replacement, which frequently appears in the cryptographic problem setting, including the verification of measurement-based quantum computation. Suppose that  $n+1$ binary random variables
$n+1$ binary random variables  $X_1,\ldots, X_{n+1}$ follow a permutation invariant distribution and n binary random variables
$X_1,\ldots, X_{n+1}$ follow a permutation invariant distribution and n binary random variables  $X_1,\ldots, X_{n}$ are observed. Then, we propose randomized tests with a randomization parameter for the expectation of the
$X_1,\ldots, X_{n}$ are observed. Then, we propose randomized tests with a randomization parameter for the expectation of the  $(n+1)$th random variable
$(n+1)$th random variable  $X_{n+1}$ under a given significance level
$X_{n+1}$ under a given significance level  $\delta>0$. Our randomized tests significantly improve the upper confidence limit over deterministic tests. Our problem setting commonly appears in machine learning in addition to cryptographic scenarios by considering adversarial examples. Such studies are essential for expanding the applicable area of statistics. Although this paper addresses only binary random variables, a similar significant improvement by randomized tests can be expected for general non-binary random variables.
$\delta>0$. Our randomized tests significantly improve the upper confidence limit over deterministic tests. Our problem setting commonly appears in machine learning in addition to cryptographic scenarios by considering adversarial examples. Such studies are essential for expanding the applicable area of statistics. Although this paper addresses only binary random variables, a similar significant improvement by randomized tests can be expected for general non-binary random variables.
We prove that for every locally stable and tempered pair potential  $\phi$ with bounded range, there exists a unique infinite-volume Gibbs point process on
$\phi$ with bounded range, there exists a unique infinite-volume Gibbs point process on  $\mathbb{R}^{d}$ for every activity
$\mathbb{R}^{d}$ for every activity  $\lambda < ({e}^{L} \hat{C}_{\phi})^{-1}$, where L is the local stability constant and
$\lambda < ({e}^{L} \hat{C}_{\phi})^{-1}$, where L is the local stability constant and  $\hat{C}_{\phi} \,:\!=\, \sup_{x \in \mathbb{R}^{d}} \int_{\mathbb{R}^{d}} 1 - {e}^{-\left\lvert \phi(x, y) \right\rvert} \mathrm{d} y$ is the (weak) temperedness constant. Our result extends the uniqueness regime that is given by the classical Ruelle–Penrose bound by a factor of at least
$\hat{C}_{\phi} \,:\!=\, \sup_{x \in \mathbb{R}^{d}} \int_{\mathbb{R}^{d}} 1 - {e}^{-\left\lvert \phi(x, y) \right\rvert} \mathrm{d} y$ is the (weak) temperedness constant. Our result extends the uniqueness regime that is given by the classical Ruelle–Penrose bound by a factor of at least  ${e}$, where the improvements become larger as the negative parts of the potential become more prominent (i.e. for attractive interactions at low temperature). Our technique is based on the approach of Dyer et al. (2004 Random Structures & Algorithms 24, 461–479): We show that for any bounded region and any boundary condition, we can construct a Markov process (in our case spatial birth–death dynamics) that converges rapidly to the finite-volume Gibbs point process while the effects of the boundary condition propagate sufficiently slowly. As a result, we obtain a spatial mixing property that implies uniqueness of the infinite-volume Gibbs measure.
${e}$, where the improvements become larger as the negative parts of the potential become more prominent (i.e. for attractive interactions at low temperature). Our technique is based on the approach of Dyer et al. (2004 Random Structures & Algorithms 24, 461–479): We show that for any bounded region and any boundary condition, we can construct a Markov process (in our case spatial birth–death dynamics) that converges rapidly to the finite-volume Gibbs point process while the effects of the boundary condition propagate sufficiently slowly. As a result, we obtain a spatial mixing property that implies uniqueness of the infinite-volume Gibbs measure.
A non-uniqueness phase for infinite clusters is proven for a class of marked random connection models (RCMs) on the d-dimensional hyperbolic space,  ${\mathbb{H}^d}$, in a high volume-scaling regime. The approach taken in this paper utilizes the spherical transform on
${\mathbb{H}^d}$, in a high volume-scaling regime. The approach taken in this paper utilizes the spherical transform on  ${\mathbb{H}^d}$ to diagonalize convolution by the adjacency function and the two-point function and bound their
${\mathbb{H}^d}$ to diagonalize convolution by the adjacency function and the two-point function and bound their  $L^2\to L^2$ operator norms. Under some circumstances, this spherical transform approach also provides bounds on the triangle diagram that allows for a derivation of certain mean-field critical exponents. In particular, the results are applied to some Boolean and weight-dependent hyperbolic RCMs. While most of the paper is concerned with the high volume-scaling regime, the existence of the non-uniqueness phase is also proven without this scaling for some RCMs whose resulting graphs are almost surely not locally finite.
$L^2\to L^2$ operator norms. Under some circumstances, this spherical transform approach also provides bounds on the triangle diagram that allows for a derivation of certain mean-field critical exponents. In particular, the results are applied to some Boolean and weight-dependent hyperbolic RCMs. While most of the paper is concerned with the high volume-scaling regime, the existence of the non-uniqueness phase is also proven without this scaling for some RCMs whose resulting graphs are almost surely not locally finite.