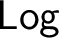Refine search
Actions for selected content:
30 results
Papers on weak first-order theories and decidability problems
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 31 / Issue 4 / December 2025
- Published online by Cambridge University Press:
- 15 December 2025, p. 696
- Print publication:
- December 2025
-
- Article
-
- You have access
- Export citation
Comparison of language models for wine sentiment analysis
-
- Journal:
- Journal of Wine Economics / Volume 20 / Issue 4 / November 2025
- Published online by Cambridge University Press:
- 13 October 2025, pp. 371-384
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
7 - Features, Case and Agreement
- from Part I - Configuration and Hierarchy
-
- Book:
- Continuing Syntax
- Published online:
- 03 October 2025
- Print publication:
- 25 September 2025, pp 139-156
-
- Chapter
- Export citation
WHEN BI-INTERPRETABILITY IMPLIES SYNONYMY
- Part of
-
- Journal:
- The Review of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 02 September 2025, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Machine Learning in Quantum Sciences
-
- Published online:
- 13 June 2025
- Print publication:
- 12 June 2025
3 - Phase classification
-
- Book:
- Machine Learning in Quantum Sciences
- Published online:
- 13 June 2025
- Print publication:
- 12 June 2025, pp 47-75
-
- Chapter
- Export citation
Identifying most important predictors for suicidal thoughts and behaviours among healthcare workers active during the Spain COVID-19 pandemic: a machine-learning approach
-
- Journal:
- Epidemiology and Psychiatric Sciences / Volume 34 / 2025
- Published online by Cambridge University Press:
- 08 May 2025, e28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Feature reassembly and meso-parameters versus interpretability: From inconsistent null subjects in L1 Hebrew to no null subjects in L2 English
-
- Journal:
- Journal of Linguistics / Volume 61 / Issue 3 / August 2025
- Published online by Cambridge University Press:
- 31 January 2025, pp. 499-534
- Print publication:
- August 2025
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On Various Causes of Improper Solutions in Maximum Likelihood Factor Analysis
-
- Journal:
- Psychometrika / Volume 43 / Issue 2 / June 1978
- Published online by Cambridge University Press:
- 01 January 2025, pp. 225-243
-
- Article
- Export citation
Generalized Structured Component Analysis Accommodating Convex Components: A Knowledge-Based Multivariate Method with Interpretable Composite Indexes
-
- Journal:
- Psychometrika / Volume 89 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 241-266
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
CERTIFIED
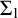 $ \Sigma _1$-SENTENCES
$ \Sigma _1$-SENTENCES
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 12 December 2024, pp. 1-29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we study the employment of
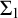 $\Sigma _1$-sentences with certificates, i.e.,
$\Sigma _1$-sentences with certificates, i.e., 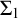 $\Sigma _1$-sentences where a number of principles is added to ensure that the witness is sufficiently number-like. We develop certificates in some detail and illustrate their use by reproving some classical results and proving some new ones. An example of such a classical result is Vaught’s theorem of the strong effective inseparability of
$\Sigma _1$-sentences where a number of principles is added to ensure that the witness is sufficiently number-like. We develop certificates in some detail and illustrate their use by reproving some classical results and proving some new ones. An example of such a classical result is Vaught’s theorem of the strong effective inseparability of 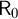 $\mathsf {R}_0$.
$\mathsf {R}_0$.We also develop the new idea of a theory being
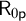 $\mathsf {R}_{0\mathsf {p}}$-sourced. Using this notion, we can transfer a number of salient results from
$\mathsf {R}_{0\mathsf {p}}$-sourced. Using this notion, we can transfer a number of salient results from 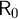 $\mathsf {R}_0$ to a variety of other theories.
$\mathsf {R}_0$ to a variety of other theories.
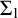
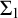
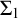
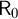
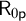
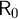
Decoder decomposition for the analysis of the latent space of nonlinear autoencoders with wind-tunnel experimental data
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 09 December 2024, e38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
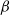 $\beta$-wave-based exploration of sensitive EEG features and classification of situation awareness
$\beta$-wave-based exploration of sensitive EEG features and classification of situation awareness
-
- Journal:
- The Aeronautical Journal / Volume 128 / Issue 1329 / November 2024
- Published online by Cambridge University Press:
- 09 May 2024, pp. 2561-2576
-
- Article
- Export citation
-
The purpose of this study was to explore the electroencephalogram (EEG) features sensitive to situation awareness (SA) and then classify SA levels. Forty-eight participants were recruited to complete an SA standard test based on the multi-attribute task battery (MATB) II, and the corresponding EEG data and situation awareness global assessment technology (SAGAT) scores were recorded. The population with the top 25% of SAGAT scores was selected as the high-SA level (HSL) group, and the bottom 25% was the low-SA level (LSL) group. The results showed that (1) for the relative power of
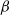 $\beta$1 (16–20Hz),
$\beta$1 (16–20Hz), 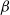 $\beta$2 (20–24Hz) and
$\beta$2 (20–24Hz) and 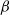 $\beta$3 (24–30Hz), repeated measures analysis of variance (ANOVA) in three brain regions (Central Central-Parietal, and Parietal) × three brain lateralities (left, midline, and right) × two SA groups (HSL and LSL) showed a significant main effect for SA groups; post hoc comparisons revealed that compared with LSL, the above features of HSL were higher. (2) for most ratio features associated with
$\beta$3 (24–30Hz), repeated measures analysis of variance (ANOVA) in three brain regions (Central Central-Parietal, and Parietal) × three brain lateralities (left, midline, and right) × two SA groups (HSL and LSL) showed a significant main effect for SA groups; post hoc comparisons revealed that compared with LSL, the above features of HSL were higher. (2) for most ratio features associated with 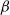 $\beta$1 ∼
$\beta$1 ∼ 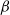 $\beta$3, ANOVA also revealed a main effect for SA groups. (3) EEG features sensitive to SA were selected to classify SA levels with small-sample data based on the general supervised machine learning classifiers. Five-fold cross-validation results showed that among the models with easy interpretability, logistic regression (LR) and decision tree (DT) presented the highest accuracy (both 92%), while among the models with hard interpretability, the accuracy of random forest (RF) was 88.8%, followed by an artificial neural network (ANN) of 84%. The above results suggested that (1) the relative power of
$\beta$3, ANOVA also revealed a main effect for SA groups. (3) EEG features sensitive to SA were selected to classify SA levels with small-sample data based on the general supervised machine learning classifiers. Five-fold cross-validation results showed that among the models with easy interpretability, logistic regression (LR) and decision tree (DT) presented the highest accuracy (both 92%), while among the models with hard interpretability, the accuracy of random forest (RF) was 88.8%, followed by an artificial neural network (ANN) of 84%. The above results suggested that (1) the relative power of 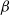 $\beta$1 ∼
$\beta$1 ∼ 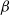 $\beta$3 and their associated ratios were sensitive to changes in SA levels; (2) the general supervised machine learning models all exhibited good accuracy (greater than 75%); and (3) furthermore, LR and DT are recommended by combining the interpretability and accuracy of the models.
$\beta$3 and their associated ratios were sensitive to changes in SA levels; (2) the general supervised machine learning models all exhibited good accuracy (greater than 75%); and (3) furthermore, LR and DT are recommended by combining the interpretability and accuracy of the models.
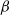
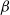
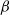
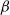
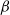
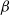
TREE THEORY: INTERPRETABILITY BETWEEN WEAK FIRST-ORDER THEORIES OF TREES
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 29 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 10 February 2023, pp. 465-502
- Print publication:
- December 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Elementary first-order theories of trees allowing at most, exactly
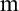 $\mathrm{m}$, and any finite number of immediate descendants are introduced and proved mutually interpretable among themselves and with Robinson arithmetic, Adjunctive Set Theory with Extensionality and other well-known weak theories of numbers, sets, and strings.
$\mathrm{m}$, and any finite number of immediate descendants are introduced and proved mutually interpretable among themselves and with Robinson arithmetic, Adjunctive Set Theory with Extensionality and other well-known weak theories of numbers, sets, and strings.
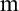
2 - Automating Supervision of AI Delegates
- from Part I - Foundations of Responsible AI
-
-
- Book:
- The Cambridge Handbook of Responsible Artificial Intelligence
- Published online:
- 28 October 2022
- Print publication:
- 17 November 2022, pp 19-30
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
MUTUAL INTERPRETABILITY OF WEAK ESSENTIALLY UNDECIDABLE THEORIES
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 18 February 2022, pp. 1374-1395
- Print publication:
- December 2022
-
- Article
- Export citation
The accuracy versus interpretability trade-off in fraud detection model
-
- Journal:
- Data & Policy / Volume 3 / 2021
- Published online by Cambridge University Press:
- 05 July 2021, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
THE POSET OF ALL LOGICS II: LEIBNIZ CLASSES AND HIERARCHY
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 88 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 10 June 2021, pp. 324-362
- Print publication:
- March 2023
-
- Article
- Export citation
THE POSET OF ALL LOGICS I: INTERPRETATIONS AND LATTICE STRUCTURE
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 86 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 10 June 2021, pp. 935-964
- Print publication:
- September 2021
-
- Article
- Export citation
-
A notion of interpretation between arbitrary logics is introduced, and the poset
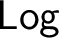 $\mathsf {Log}$ of all logics ordered under interpretability is studied. It is shown that in
$\mathsf {Log}$ of all logics ordered under interpretability is studied. It is shown that in 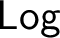 $\mathsf {Log}$ infima of arbitrarily large sets exist, but binary suprema in general do not. On the other hand, the existence of suprema of sets of equivalential logics is established. The relations between
$\mathsf {Log}$ infima of arbitrarily large sets exist, but binary suprema in general do not. On the other hand, the existence of suprema of sets of equivalential logics is established. The relations between 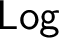 $\mathsf {Log}$ and the lattice of interpretability types of varieties are investigated.
$\mathsf {Log}$ and the lattice of interpretability types of varieties are investigated.