


1. Introduction
People rarely make decisions in isolation. Often, the choices of friends, family, and acquaintances shape our beliefs and behavior. This observation forms the basis for a growing body of research examining the impact of social influence on individual decision-making and collective outcomes.Footnote 1 Network games, in which agents in a social network play a game where their payoffs depend on their own actions and the actions of their network neighbors, capture situations where the costs and benefits of our choices depend directly on the decisions of our social contacts (Galeotti et al., Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010).
This paper builds on the network games framework to incorporate an additional feature of social decision-making: people’s actions tend to be locally correlated, and this local correlation in turn affects how information and behaviors spread. We expect local correlation to arise in a variety of contexts. For example, two colleagues are likely to use a common software package because it facilitates collaboration, while individuals in another firm or department might use an alternative. This effect gives rise to local positive correlation in software choice and may inhibit diffusion of a novel alternative. In other cases, social influence may lead to locally negatively correlated behavior; if we can count on a particular parent to volunteer in our child’s classroom then we may be more likely not to volunteer and instead free-ride off of their generosity. Moreover, local correlation changes the way that behaviors and information spread. In the case of software choice for example, if it were not for local correlation most people would be forced to adopt the most popular software, but local correlation allows different pockets of people to make different choices.
While previous models of network games capture how some features of social networks, such as the degree distribution, relate to social influence (Jackson and Yariv, Reference Jackson and Yariv2007; Galeotti et al., Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010), this paper extends that framework to account for local correlation. A fundamental challenge in such a model is that there are many potential equilibria depending on details of the network of connections. As in prior models of network games, we introduce an incomplete information structure to help solve the equilibrium selection problem (Jackson and Yariv, Reference Jackson and Yariv2007; Galeotti et al., Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010), but unlike existing models our approach keeps track of local correlation in agents’ strategies. Specifically, agents do not know the specific identities of their neighbors, but they use their own current actions and knowledge of population level correlations to guess at the likely actions of their neighbors.
This information structure corresponds with many real world situations. For example, if I work in a firm where a particular software package is standard, I may not know who I will work with on my next project, but I am more likely than not to work with someone using the same software package I use because of local correlation in software choice. The same could be said for collaborations among academics in different departments or disciplines. Similarly, if I tend to volunteer in my child’s classroom, I may not know which other parents’ children will share a classroom with my child next year, but I can expect them to be less likely to volunteer because they can count on me to do so.
Motivated by these examples, we apply the model to two classes of games, games of strategic complements and games of strategic substitutes, and show that including local correlation in the model increases the social efficiency of predicted equilibrium outcomes. These two classes of games include any game in which agents play independently with each of their neighbors and receive the sum of the separate payoffs, as well as other games such as the
 $k$
-person stag hunt and the best-shot public goods game. Intuitively, games of strategic complements correspond to situations in which agents prefer to take an action when more of their neighbors also take that action. One potential application of these games is as a model of technology adoption. In games of strategic complements, agents rapidly split into clusters using a locally standard strategy, and eventually the entire population settles on a single choice. Either of the winner-take-all equilibria are possible, and they are separated by a “critical mass” tipping point (Ball, Reference Ball2004; Lamberson and Page, Reference Lamberson and Page2012). Games of strategic substitutes, which capture public goods games in which agents prefer to take an action more when fewer of their neighbors take that action, tend towards a unique equilibrium. Agents’ strategies are locally dissociative. For example, if we think of the model as capturing provision of a public good, a few agents serve the role of local providers of the good while their neighbors free ride.
$k$
-person stag hunt and the best-shot public goods game. Intuitively, games of strategic complements correspond to situations in which agents prefer to take an action when more of their neighbors also take that action. One potential application of these games is as a model of technology adoption. In games of strategic complements, agents rapidly split into clusters using a locally standard strategy, and eventually the entire population settles on a single choice. Either of the winner-take-all equilibria are possible, and they are separated by a “critical mass” tipping point (Ball, Reference Ball2004; Lamberson and Page, Reference Lamberson and Page2012). Games of strategic substitutes, which capture public goods games in which agents prefer to take an action more when fewer of their neighbors take that action, tend towards a unique equilibrium. Agents’ strategies are locally dissociative. For example, if we think of the model as capturing provision of a public good, a few agents serve the role of local providers of the good while their neighbors free ride.
In addition to incorporating local correlation, we also extend our framework to take network clustering into account. In many empirical settings two agents that share a mutual friend are likely to be friends of each other (Newman and Park, Reference Newman and Park2003). We adjust the model to incorporate clustering (also known as transitivity and triadic closure) and examine the dependence of predicted equilibria in games of complements and substitutes on clustering as quantified by the clustering coefficient of the network. We find that in the case of public goods provision, clustered networks result in fewer agents providing the public good than non-clustered networks. In games of complements, clustering allows markets to be shared between two different standards.
This paper builds on and contributes to three streams of literature. An expanding body of research addresses the role of social influence and network structure in economics. Much of this research employs a partial information structure based on a “mean-field approximation” to solve the equilibrium selection problem, which discards local correlation and clustering information (Jackson and Yariv, Reference Jackson and Yariv2007; Jackson and Rogers, Reference Jackson and Rogers2007; López-Pintado, Reference López-Pintado2008; Galeotti et al., Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010; Lamberson, Reference Lamberson2010, Reference Lamberson2011; Feri and Pin, Reference Feri and Pin2020). The primary advance of our model over previous work in this area is the inclusion of local correlation and clustering. In each of these previous papers, agents play as if their neighbors are random draws from the population at large conditional on the agents’ degree but with no conditioning on their own current strategy. Because both local correlation and network clustering are well-known features of real social networks, exploring the contribution of these features to strategy dynamics in network games is an important contribution of this paper.Footnote 2
The mathematics of our approach draws primarily on literature in theoretical ecology, where similar methods are employed to model, for example, the spread of disease (Matsuda et al., Reference Matsuda, Ogita, Sasaki and Satö1992; Keeling et al., Reference Keeling, Rand and Morris1997; Morris, Reference Morris1997; Van Baalen, Reference Van Baalen, Dieckmann, Law and Metz2000). Rather than taking a partial information interpretation, the analogous model in biology (referred to variously as a “pair approximation” or “correlation model”) is instead thought of as an approximation to a diffusion process occurring in a fixed contact network. Similarly, our model could also be interpreted as an approximation to agents’ behavior in a fixed network. In comparison to other approximations that do not consider local correlation, this method better approximates real and simulated diffusion patterns (Keeling et al., Reference Keeling, Rand and Morris1997; Morris, Reference Morris1997; Van Baalen, Reference Van Baalen, Dieckmann, Law and Metz2000; Newman, Reference Newman2018; Lamberson, Reference Lamberson2018).
Finally, our paper is related to research on evolutionary games in networks, where pair approximation methods have also been employed. (Morris, Reference Morris1997; Ohtsuki et al., Reference Ohtsuki, Hauert, Lieberman and Nowak2006; Ohtsuki and Nowak, Reference Ohtsuki and Nowak2006). As in the evolutionary game theory literature, we impose a specific dynamic on agents’ strategy updating to help solve the equilibrium selection problem (Foster and Young, Reference Foster and Young1990; Kandori et al., Reference Kandori, Mailath and Rob1993). In this paper, we consider two dynamics: best response and an imitation rule. Typical dynamics in evolutionary game theory assume that the probability that an agent switches strategies derives from the payoffs (i.e. fitness) of other agents. Intuitively, when an agent dies more fit strategies are more likely to invade the resulting opening. Most of our analysis focuses on best response dynamics, so an agent only switches strategies if doing so is a best response for them. In other words, in our framework an agent bases their choice of strategy on their own payoffs rather than those of their neighbors. However, best response dynamics introduces a discontinuity in the model that makes analytically solving for equilibria more challenging, and so our results under best response dynamics are based on numerical computations. For comparison, we also consider an imitation rule in Appendix A in which agents are more likely to imitate higher payoff strategies. As shown by Choi et al. (Reference Choi, Goyal, Guo and Moisan2024), in some situations such an imitation rule may better describe actual human behavior than best response dynamics. Moreover, the imitation rule allows us to apply previous results from the evolutionary game theory literature and obtain analytic solutions to the model. As we show, the structure of these equilibria matches the numeric results found under best response dynamics.
Our paper also relates to a parallel experimental literature on games played in networks (Choi et al., Reference Choi, Gallo and Kariv2016). For example, Judd et al. (Reference Judd, Kearns and Vorobeychik2010) consider the effect of clustering on coordination games and find that higher levels of network clustering increase local coordination at the expense of global coordination. This matches the theoretical prediction for the effect of clustering on equilibria in games of strategic complements described in Section 6. Gallo and Yan (Reference Gallo and Yan2015) examine subjects playing a prisoner’s dilemma game in a setting where they are allowed to both form and cut links in their network. In contrast to the predictions of our model in a fixed network, they find that cooperation is higher in more clustered structures, but this could result in part from the ability of subjects to choose their neighbors in the experiment. Charness et al. (Reference Charness, Feri, Meléndez-Jiménez and Sutter2014) design experiments to explicitly mimic the theoretical setup of Galeotti et al. (Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010). They find that in both games of strategic complements and strategic substitutes, increased network clustering increases the tendency of subjects to choose efficient equilibria. (See also Keser, Reference Keser2002 and Berninghaus et al., Reference Berninghaus, Ehrhart and Keser2002.) These results match ours for games of strategic substitutes, but only partially for games of strategic complements, where the predicted effect of clustering on efficiency depends on initial conditions in our model.
The rest of the paper proceeds as follows. Section 2 defines the model and derives differential equations that describe the evolution of play in the population over time. Section 4 applies the framework to understand patterns of play in games of strategic complements and substitutes using numerical computations. Section 5 considers the implications of the model for the evolution of local correlation in agents’ actions. In Section 6, we extend the model to account for network clustering and examine how clustering effects equilibrium outcomes in games of substitutes and complements. Section 7 concludes the paper and suggests extensions for future research. In the first of two appendices we consider analytic solutions of the model using imitation dynamics and show that the structure of equilibria matches the numerical results under best response dynamics. In the second appendix, we use agent-based simulations to validate and extend our analysis.
2. The model
We consider a finite population of agents
 $1,\ldots ,n$
. For each agent
$1,\ldots ,n$
. For each agent
 $i$
there is a collection of other agents
$i$
there is a collection of other agents
 $N(i)\subset \{1,\ldots ,n\}\setminus \{i\}$
, that we call the friends or neighbors of
$N(i)\subset \{1,\ldots ,n\}\setminus \{i\}$
, that we call the friends or neighbors of
 $i$
. Friendship is reciprocal, so
$i$
. Friendship is reciprocal, so
 $j\in N(i)$
implies
$j\in N(i)$
implies
 $i \in N(j)$
. This information defines a network with nodes the agents
$i \in N(j)$
. This information defines a network with nodes the agents
 $i=1,\ldots ,n$
, and a link from
$i=1,\ldots ,n$
, and a link from
 $i$
to
$i$
to
 $j$
if
$j$
if
 $j\in N(i)$
(Jackson, Reference Jackson2008; Newman, Reference Newman2018).
$j\in N(i)$
(Jackson, Reference Jackson2008; Newman, Reference Newman2018).
At each time step
 $t=1,2,3,\ldots$
each agent
$t=1,2,3,\ldots$
each agent
 $i$
chooses an action
$i$
chooses an action
 $\sigma _i\in \{x,y\}$
(we suppress the dependence on time). An agent’s payoff at each time depends on their own action and those of their neighbors as specified by the payoff function
$\sigma _i\in \{x,y\}$
(we suppress the dependence on time). An agent’s payoff at each time depends on their own action and those of their neighbors as specified by the payoff function
 $\pi (\sigma _i,\sigma _{N(i)})$
. For an agent
$\pi (\sigma _i,\sigma _{N(i)})$
. For an agent
 $i$
, let
$i$
, let
 $k_x(i)$
and
$k_x(i)$
and
 $k_y(i)$
denote the number of neighbors playing
$k_y(i)$
denote the number of neighbors playing
 $x$
and
$x$
and
 $y$
, respectively. When the focal agent is clear or unimportant, we drop the dependence on
$y$
, respectively. When the focal agent is clear or unimportant, we drop the dependence on
 $i$
, and simply write
$i$
, and simply write
 $k_x$
or
$k_x$
or
 $k_y$
. We assume that payoffs are anonymous in the sense that they depend only on the number of neighbors playing each of the two strategies, not on their specific identities. In this case, the payoffs can be specified by two payoff functions:
$k_y$
. We assume that payoffs are anonymous in the sense that they depend only on the number of neighbors playing each of the two strategies, not on their specific identities. In this case, the payoffs can be specified by two payoff functions:
 $\pi _x(k_x,k_y)$
and
$\pi _x(k_x,k_y)$
and
 $\pi _y(k_x,k_y)$
, the payoffs to playing strategy
$\pi _y(k_x,k_y)$
, the payoffs to playing strategy
 $x$
or
$x$
or
 $y$
, respectively, when an agent has
$y$
, respectively, when an agent has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
and
$x$
and
 $k_y$
neighbors playing
$k_y$
neighbors playing
 $y$
.
$y$
.
To simplify the analysis, assume that each agent has a fixed number of neighbors,
 $k$
(or equivalently, each agent plays with the expectation of meeting a fixed number of agents on average).Footnote
3
Then we can write the payoffs as functions of the number of neighbors playing strategy
$k$
(or equivalently, each agent plays with the expectation of meeting a fixed number of agents on average).Footnote
3
Then we can write the payoffs as functions of the number of neighbors playing strategy
 $x$
:
$x$
:
 $\pi _{x}(k_x)$
and
$\pi _{x}(k_x)$
and
 $\pi _{y}(k_x)$
.
$\pi _{y}(k_x)$
.
Agents in the model update their actions using a best response rule similar to the dynamics studied by Blume (Reference Blume1995). At each time step, an agent is chosen uniformly at random to update their strategy. We assume that agents are myopic and only attempt to maximize their next period payoffs. Thus, because only one agent updates at a time, it is rational for the agent to choose the best response to the play of their neighbors in the previous period. Since payoffs are determined entirely by the number of neighbors playing
 $x$
, we can define the best response function,
$x$
, we can define the best response function,
 $BR:\{0,\ldots ,n\}\to \{x,y\}$
so that
$BR:\{0,\ldots ,n\}\to \{x,y\}$
so that
 $BR(k_x)$
is the best response for an agent with
$BR(k_x)$
is the best response for an agent with
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
. When the payoffs to both strategies are equal, we arbitrarily designate
$x$
. When the payoffs to both strategies are equal, we arbitrarily designate
 $x$
as the best response.
$x$
as the best response.
Example 1. Pairwise games
One example that fits within this framework is a situation in which agents play a symmetric binary game with each of their neighbors in which they are constrained to play the same strategy with all of their neighbors at any given time, and they receive the sum of the payoffs from each of these pairwise interactions. For example, suppose that for each of an agent
 $i$
’s neighbors
$i$
’s neighbors
 $j\in N_i$
,
$j\in N_i$
,
 $i$
receives payoffs depending on
$i$
receives payoffs depending on
 $\sigma _i$
and
$\sigma _i$
and
 $\sigma _j$
as specified in Table 1.
$\sigma _j$
as specified in Table 1.
Table 1. Payoffs to agent
 $i$
from agent
$i$
from agent
 $j$
$j$

Then
 $\pi _x(k_x,k_y)=k_xa+k_yb$
and
$\pi _x(k_x,k_y)=k_xa+k_yb$
and
 $\pi _y(k_x,k_y)=k_xc+k_yd$
. In this case, the best response function follows a threshold rule:
$\pi _y(k_x,k_y)=k_xc+k_yd$
. In this case, the best response function follows a threshold rule:
 \begin{equation} BR(k_x,k_y)=\begin{cases} x & k_x(a-c)\geq k_y(d-b)\\[5pt] y & k_x(a-c)\lt k_y(d-b) \end{cases} \end{equation}
\begin{equation} BR(k_x,k_y)=\begin{cases} x & k_x(a-c)\geq k_y(d-b)\\[5pt] y & k_x(a-c)\lt k_y(d-b) \end{cases} \end{equation}
If
 $a-b-c+d\gt 0$
, the action
$a-b-c+d\gt 0$
, the action
 $x$
becomes more attractive as more of an agent’s neighbors play
$x$
becomes more attractive as more of an agent’s neighbors play
 $x$
and, as we will show below, agents tend to coordinate locally on a given strategy. When
$x$
and, as we will show below, agents tend to coordinate locally on a given strategy. When
 $a-b-c+d\lt 0$
, agents prefer to play
$a-b-c+d\lt 0$
, agents prefer to play
 $x$
unless too many of their neighbors are also playing
$x$
unless too many of their neighbors are also playing
 $x$
. In this situation we find that agents’ strategies tend to be locally negatively correlated.
$x$
. In this situation we find that agents’ strategies tend to be locally negatively correlated.
Example 2.
 $\boldsymbol{k}$
-person stag hunt
$\boldsymbol{k}$
-person stag hunt
The framework also allows for situations in which an agent’s payoffs depend on the play of their entire network neighborhood such as the
 $k$
-person stag hunt (Skyrms, Reference Skyrms2003). In this game, an agent receives a payoff of 1 from playing
$k$
-person stag hunt (Skyrms, Reference Skyrms2003). In this game, an agent receives a payoff of 1 from playing
 $x$
if more than
$x$
if more than
 $\tau$
of their neighbors also play
$\tau$
of their neighbors also play
 $x$
, but receives 0 from playing
$x$
, but receives 0 from playing
 $x$
otherwise. Playing
$x$
otherwise. Playing
 $y$
yields a payoff
$y$
yields a payoff
 $\alpha \lt 1$
independent of the play of the agents’ neighbors. Here again the best response function follows a simple threshold rule: if
$\alpha \lt 1$
independent of the play of the agents’ neighbors. Here again the best response function follows a simple threshold rule: if
 $k_x\gt \tau$
play
$k_x\gt \tau$
play
 $x$
, otherwise play
$x$
, otherwise play
 $y$
.
$y$
.
Example 3. Best-shot public goods game
In the
 $k$
-person stag hunt there is pressure for agents to conform with the actions of their neighbors. In the best-shot public goods game, agents would always prefer for their neighbors to provide the public good while they free ride, but they would rather provide the public good themselves if none of their neighbors is willing to do so. Specifically, playing
$k$
-person stag hunt there is pressure for agents to conform with the actions of their neighbors. In the best-shot public goods game, agents would always prefer for their neighbors to provide the public good while they free ride, but they would rather provide the public good themselves if none of their neighbors is willing to do so. Specifically, playing
 $x$
yields a payoff of
$x$
yields a payoff of
 $1-c$
for some
$1-c$
for some
 $c\in (0,1)$
, while playing
$c\in (0,1)$
, while playing
 $y$
has a payoff of 1 as long as at least one of the agent’s neighbors plays
$y$
has a payoff of 1 as long as at least one of the agent’s neighbors plays
 $x$
and a payoff of 0 otherwise. This game captures the incentives in situations like volunteering to be the “room parent” for a child’s class, where only one agent needs to pay the cost of providing the public good in order for all of their neighbors to reap the benefits.
$x$
and a payoff of 0 otherwise. This game captures the incentives in situations like volunteering to be the “room parent” for a child’s class, where only one agent needs to pay the cost of providing the public good in order for all of their neighbors to reap the benefits.
3. Information
Even in small populations with simple network structures this model often admits a multitude of equilibria. To help solve the equilibrium selection problem, we assume agents only have partial information about the play of their neighbors. Galeotti et al. (Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010) use a similar strategy by assuming that agents know the probability that their neighbors play a given strategy conditional on their own degree. Effectively, the agents know how many people they expect to interact with but not their specific identities. Here we employ an alternative strategy that allows us to retain local correlation in neighbors’ actions. Specifically, agents know the probability that their neighbors play a given strategy conditional on their own action.
One way to understand the difference between these two approaches is to think of them as compartmental models (similar to standard models of disease spread such as the SI, SIS, and SIR models (Bailey, Reference Bailey1975). Jackson and Yariv (Reference Jackson and Yariv2006); Jackson and Rogers (Reference Jackson and Rogers2007), and López-Pintado (Reference López-Pintado2008) apply direct analogs of these models in economics). The approach employed by Galeotti et al. (Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010) has compartments for each strategy for each degree type and models the flows between these types (more specifically, they consider equilibrium states of such a flow). Our model has compartments for each pair type – e.g.
 $xx$
,
$xx$
,
 $xy$
and
$xy$
and
 $yy$
connected pairs—and keeps track of transitions between these pair types. For this reason, our approach is often called a pair approximation.
$yy$
connected pairs—and keeps track of transitions between these pair types. For this reason, our approach is often called a pair approximation.
We use the first three Greek letters as variables to denote either of the two strategies:
 $\alpha ,\beta ,\gamma \in \{x,y\}$
. Let
$\alpha ,\beta ,\gamma \in \{x,y\}$
. Let
 $p_{\alpha }$
denote the proportion of agents in the population playing strategy
$p_{\alpha }$
denote the proportion of agents in the population playing strategy
 $\alpha$
. Let
$\alpha$
. Let
 $p_{\alpha \beta }$
denote the proportion of connected ordered pairs of agents in the network with the first agent playing
$p_{\alpha \beta }$
denote the proportion of connected ordered pairs of agents in the network with the first agent playing
 $\alpha$
and the second agent playing
$\alpha$
and the second agent playing
 $\beta$
. Because we use ordered pairs,
$\beta$
. Because we use ordered pairs,
 $p_{xy}=p_{yx}$
. Let
$p_{xy}=p_{yx}$
. Let
 $p_{\alpha |\beta }$
denote the probability that a random neighbor of an agent playing strategy
$p_{\alpha |\beta }$
denote the probability that a random neighbor of an agent playing strategy
 $\beta$
is playing strategy
$\beta$
is playing strategy
 $\alpha$
. Note that the following relationships hold among these variables:
$\alpha$
. Note that the following relationships hold among these variables:
 \begin{align} p_x+p_{y}&=1 \end{align}
\begin{align} p_x+p_{y}&=1 \end{align}
 \begin{align} p_{xx}+2p_{xy}+p_{yy}&=1 \end{align}
\begin{align} p_{xx}+2p_{xy}+p_{yy}&=1 \end{align}
 \begin{align} p_{x|\alpha }+p_{y|\alpha }&=1 \end{align}
\begin{align} p_{x|\alpha }+p_{y|\alpha }&=1 \end{align}
 \begin{align} p_{\alpha \beta }&=p_{\alpha |\beta }p_{\beta }. \end{align}
\begin{align} p_{\alpha \beta }&=p_{\alpha |\beta }p_{\beta }. \end{align}
The last equation follows from Bayes’ rule.
In a given time step only one agent updates their strategy, so if
 $p_x$
changes it increases or decreases by
$p_x$
changes it increases or decreases by
 $1/N$
. The probability that
$1/N$
. The probability that
 $p_x$
increases equals the probability that the agent selected to update their strategy is currently playing
$p_x$
increases equals the probability that the agent selected to update their strategy is currently playing
 $y$
,
$y$
,
 $p_{y}$
, times the probability that the best response for that agent is
$p_{y}$
, times the probability that the best response for that agent is
 $x$
,
$x$
,
 $P[k_x\in BR^{-1}(x)]$
. We need to calculate the probability that a random agent playing
$P[k_x\in BR^{-1}(x)]$
. We need to calculate the probability that a random agent playing
 $y$
has
$y$
has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
. Let
$x$
. Let
 $i$
be the agent chosen to update their strategy and suppose that
$i$
be the agent chosen to update their strategy and suppose that
 $i$
is playing strategy
$i$
is playing strategy
 $y$
. Then the probability that a random neighbor of
$y$
. Then the probability that a random neighbor of
 $i$
is playing
$i$
is playing
 $x$
is
$x$
is
 $p_{x|y}$
, and the probability that a random neighbor of
$p_{x|y}$
, and the probability that a random neighbor of
 $i$
plays
$i$
plays
 $y$
is
$y$
is
 $p_{y|y}$
. If (conditional on
$p_{y|y}$
. If (conditional on
 $i$
playing
$i$
playing
 $y$
) the strategies of
$y$
) the strategies of
 $i$
’s neighbors are independent then the probability that
$i$
’s neighbors are independent then the probability that
 $i$
has
$i$
has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
and
$x$
and
 $k_y=k-k_x$
neighbors playing
$k_y=k-k_x$
neighbors playing
 $y$
is
$y$
is
 \begin{equation} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y}. \end{equation}
\begin{equation} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y}. \end{equation}
In general,
 $i$
’s neighbors will not be (conditionally) independent. In empirical social networks, two individuals with a common friend are much more likely to be friends with each other than two randomly chosen individuals (Newman and Park, Reference Newman and Park2003). This feature, known as clustering or transitivity (Jackson, Reference Jackson2008), implies that often the state of two neighbors of a given node will affect one another directly. Thus, calculating the probability that
$i$
’s neighbors will not be (conditionally) independent. In empirical social networks, two individuals with a common friend are much more likely to be friends with each other than two randomly chosen individuals (Newman and Park, Reference Newman and Park2003). This feature, known as clustering or transitivity (Jackson, Reference Jackson2008), implies that often the state of two neighbors of a given node will affect one another directly. Thus, calculating the probability that
 $i$
has
$i$
has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
and
$x$
and
 $k_y$
neighbors playing
$k_y$
neighbors playing
 $y$
requires knowing the probability of larger configurations such as
$y$
requires knowing the probability of larger configurations such as
 $p_{x|yx}$
—the probability that an agent plays
$p_{x|yx}$
—the probability that an agent plays
 $x$
given that they neighbor an agent playing
$x$
given that they neighbor an agent playing
 $y$
that has another neighbor playing
$y$
that has another neighbor playing
 $x$
. To keep track of these probabilities requires tracking the frequency of triple configurations in the network, which in turn requires knowing the frequency of quadruples and so on. Rather than continue this expansion, we stop here and make the assumption that the agents behave as if the actions of their neighbors are independent conditional on their own actions. Thus,
$x$
. To keep track of these probabilities requires tracking the frequency of triple configurations in the network, which in turn requires knowing the frequency of quadruples and so on. Rather than continue this expansion, we stop here and make the assumption that the agents behave as if the actions of their neighbors are independent conditional on their own actions. Thus,
 $p_{\alpha |\beta \gamma }$
is simply
$p_{\alpha |\beta \gamma }$
is simply
 $p_{\alpha |\beta }$
. We call this the conditionally independent neighbors (CIN) assumption.
$p_{\alpha |\beta }$
. We call this the conditionally independent neighbors (CIN) assumption.
If the network is a tree (i.e. has no closed loops), this assumption follows from the fact that the only path between two neighbors of an agent
 $i$
goes through
$i$
goes through
 $i$
. The assumption is also approximately true in large Poisson random networks, because these networks have few short loops (Newman, Reference Newman2018).Footnote
4
In general, however, this will not be the case. Nevertheless, the CIN assumption has proven to lead to highly accurate approximations in other models, even in clustered networks (Morris, Reference Morris1997; Newman, Reference Newman2018). Under this assumption, equation (6) gives the probability that an agent playing
$i$
. The assumption is also approximately true in large Poisson random networks, because these networks have few short loops (Newman, Reference Newman2018).Footnote
4
In general, however, this will not be the case. Nevertheless, the CIN assumption has proven to lead to highly accurate approximations in other models, even in clustered networks (Morris, Reference Morris1997; Newman, Reference Newman2018). Under this assumption, equation (6) gives the probability that an agent playing
 $y$
has
$y$
has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
and
$x$
and
 $k_y$
neighbors playing
$k_y$
neighbors playing
 $y$
. In Section 6, we relax the CIN assumption and examine dependence of equilibria on network clustering.
$y$
. In Section 6, we relax the CIN assumption and examine dependence of equilibria on network clustering.
The probability that
 $p_x$
decreases equals the probability that the agent selected to update their strategy is currently playing
$p_x$
decreases equals the probability that the agent selected to update their strategy is currently playing
 $x$
,
$x$
,
 $p_x$
, times the probability that the best response for that agent is
$p_x$
, times the probability that the best response for that agent is
 $y$
,
$y$
,
 $P[k_x\in BR^{-1}(y)]$
. The probability that a random agent playing
$P[k_x\in BR^{-1}(y)]$
. The probability that a random agent playing
 $x$
has
$x$
has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
and
$x$
and
 $k_y$
neighbors playing
$k_y$
neighbors playing
 $y$
is
$y$
is
 \begin{equation} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
\begin{equation} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
Thus, the net rate of change for
 $p_x$
is
$p_x$
is
 \begin{equation} \dot {p}_x=\sum _{k_x\in BR^{-1}(x)} \frac {p_{y}}{N} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x\in BR^{-1}(y)} \frac {p_x}{N} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
\begin{equation} \dot {p}_x=\sum _{k_x\in BR^{-1}(x)} \frac {p_{y}}{N} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x\in BR^{-1}(y)} \frac {p_x}{N} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
Equation (8) does not fully specify the game dynamics because the right-hand side has the terms
 $p_{\alpha |\beta }$
, which by equation (5) depend on the pair frequencies
$p_{\alpha |\beta }$
, which by equation (5) depend on the pair frequencies
 $p_{\alpha \beta }$
.
$p_{\alpha \beta }$
.
We can write down an equation describing the rate of change of the pairs
 $p_{\alpha \beta }$
in the same way that we did for the singletons
$p_{\alpha \beta }$
in the same way that we did for the singletons
 $p_x$
. The identities in equations (2) through (5) imply that it is sufficient to consider any one of the four pair types. Consider the
$p_x$
. The identities in equations (2) through (5) imply that it is sufficient to consider any one of the four pair types. Consider the
 $xx$
pairs. Let
$xx$
pairs. Let
 $i$
be the agent randomly selected to update their strategy. If
$i$
be the agent randomly selected to update their strategy. If
 $i$
is playing strategy
$i$
is playing strategy
 $y$
and has
$y$
and has
 $k_x$
neighbors playing strategy
$k_x$
neighbors playing strategy
 $x$
, where
$x$
, where
 $k_x\in BR^{-1}(x)$
, then
$k_x\in BR^{-1}(x)$
, then
 $p_{xx}$
increases by
$p_{xx}$
increases by
 $\frac {2k_x}{kN}$
(there are
$\frac {2k_x}{kN}$
(there are
 $kN$
total pairs and the change from playing
$kN$
total pairs and the change from playing
 $y$
to
$y$
to
 $x$
creates
$x$
creates
 $2k_x$
$2k_x$
 $xx$
pairs since pairs are counted in both directions). Making use of the CIN assumption, the probability that a randomly chosen agent is of type
$xx$
pairs since pairs are counted in both directions). Making use of the CIN assumption, the probability that a randomly chosen agent is of type
 $y$
and has
$y$
and has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
equals the probability that a random agent plays
$x$
equals the probability that a random agent plays
 $y$
times the probability that an agent playing
$y$
times the probability that an agent playing
 $y$
has
$y$
has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
:
$x$
:
 \begin{equation} p_{y}\frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y}. \end{equation}
\begin{equation} p_{y}\frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y}. \end{equation}
Thus, the rate of increase of
 $p_{xx}$
is
$p_{xx}$
is
 \begin{equation} \frac {2k_x}{kN}p_{y}\frac {k!}{k_x!k_y}p_{x|y}^{k_{x}}p_{y|y}^{k_y}. \end{equation}
\begin{equation} \frac {2k_x}{kN}p_{y}\frac {k!}{k_x!k_y}p_{x|y}^{k_{x}}p_{y|y}^{k_y}. \end{equation}
A similar calculation gives the rate of decrease of
 $p_{xx}$
leading to the net rate of change
$p_{xx}$
leading to the net rate of change
 \begin{equation} \dot {p}_{xx}=\sum _{k_x\in BR^{-1}(x)} \frac {2k_x}{kN}p_{y} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x\in BR^{-1}(y)} \frac {2k_x}{kN}p_x \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
\begin{equation} \dot {p}_{xx}=\sum _{k_x\in BR^{-1}(x)} \frac {2k_x}{kN}p_{y} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x\in BR^{-1}(y)} \frac {2k_x}{kN}p_x \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
Equations (8) and (11) completely describe the strategy dynamics of the game. To distinguish this model from models without local correlation, we refer to this model as a locally correlated model and models without local correlation, such as the one developed by Galeotti et al. (Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010), as independent models.
4. Strategic complements and substitutes
In this section, we examine two specific classes of games: games of strategic complements and strategic substitutes. These two classes encompass any game in which agents play independently with each of their neighbors and receive the sum of those individual payoffs.
4.1 Strategic complements
In a game of strategic complements the payoff functions satisfy
 \begin{equation} \pi _x(k_x)-\pi _y(k_x)\geq \pi _x(k_x')-\pi _y(k_x') \end{equation}
\begin{equation} \pi _x(k_x)-\pi _y(k_x)\geq \pi _x(k_x')-\pi _y(k_x') \end{equation}
for any
 $k_x$
and
$k_x$
and
 $k_x'$
with
$k_x'$
with
 $k_x\geq k_x'$
. In other words, as the number of neighbors playing
$k_x\geq k_x'$
. In other words, as the number of neighbors playing
 $x$
increases, the change in benefits to playing
$x$
increases, the change in benefits to playing
 $x$
exceeds the change in benefits to playing
$x$
exceeds the change in benefits to playing
 $y$
.
$y$
.
4.1.1 Example: standards competition with positive externalities
Games of strategic complements provide a simple model of agents choosing between two standards with positive externalities. For example, suppose the population of agents represents the population of network scientists worldwide and each of the two strategies corresponds to the choice of a statistical software package. Links join network scientists who collaborate with one another. Assume that network scientists can only use one software package at a time and because they share files with their collaborators the benefits to using a particular package increase with the number of colleagues that use the software. Specifically, we might have
 \begin{equation} \pi _x(k_x)=f(k_x)-c_x \end{equation}
\begin{equation} \pi _x(k_x)=f(k_x)-c_x \end{equation}
and
 \begin{equation} \pi _y(k_x)=f(k-k_x)-c_y, \end{equation}
\begin{equation} \pi _y(k_x)=f(k-k_x)-c_y, \end{equation}
where
 $c_x$
and
$c_x$
and
 $c_y$
are the costs of using
$c_y$
are the costs of using
 $x$
and
$x$
and
 $y$
, respectively, and
$y$
, respectively, and
 $f$
is a non-decreasing function capturing the increasing benefits of using the same package as your collaborators.
$f$
is a non-decreasing function capturing the increasing benefits of using the same package as your collaborators.
4.1.2 Dynamics with strategic complements
In games of strategic complements, the best response function follows a threshold rule: if
 $k_x\geq \tau$
play
$k_x\geq \tau$
play
 $x$
, if
$x$
, if
 $k_x\lt \tau$
play
$k_x\lt \tau$
play
 $y$
. Equations (8) and (11) reduce to
$y$
. Equations (8) and (11) reduce to
 \begin{equation} \dot {p}_x=\sum _{k_x=\tau }^k \frac {p_{y}}{N} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=0}^{\tau -1} \frac {p_x}{N} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}, \end{equation}
\begin{equation} \dot {p}_x=\sum _{k_x=\tau }^k \frac {p_{y}}{N} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=0}^{\tau -1} \frac {p_x}{N} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}, \end{equation}
and
 \begin{equation} \dot {p}_{xx}=\sum _{k_x=\tau }^k \frac {2k_x}{kN}p_{y} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=0}^{\tau -1} \frac {2k_x}{kN}p_x \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
\begin{equation} \dot {p}_{xx}=\sum _{k_x=\tau }^k \frac {2k_x}{kN}p_{y} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=0}^{\tau -1} \frac {2k_x}{kN}p_x \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}

Figure 1. The evolution of the fraction of agents playing the preferred strategy over time in a game of strategic complements under a range of initial conditions.
From equations (15) and (16), we can immediately see two possible equilibria: all agents play
 $x$
, or all agents play
$x$
, or all agents play
 $y$
. If the network has multiple connected components, then any situation in which all the agents within any given component take the same action is also an equilibrium, because in any such state
$y$
. If the network has multiple connected components, then any situation in which all the agents within any given component take the same action is also an equilibrium, because in any such state
 $p_{x|y}=p_{y|x}=0$
. It is not obvious however whether any unsegregated equilibria exist in which some agents play
$p_{x|y}=p_{y|x}=0$
. It is not obvious however whether any unsegregated equilibria exist in which some agents play
 $x$
while others choose to play
$x$
while others choose to play
 $y$
.
$y$
.
For a given set of initial conditions, equations (15) and (16) can be numerically integrated to give the predicted evolution of play in the population over time. (Analytic solutions under an alternative updating dynamic are described in Appendix A. In Appendix B we compare the numeric solutions in the main text with simulation results.) For example, Figure 1 plots the fraction of agents playing strategy
 $x$
over time in a network with 1000 nodes each of degree ten.Footnote
5
In the figure, the best response threshold for playing strategy
$x$
over time in a network with 1000 nodes each of degree ten.Footnote
5
In the figure, the best response threshold for playing strategy
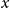 $x$
is
$x$
is
 $\tau =4$
. In other words,
$\tau =4$
. In other words,
 $x$
is the best response for any agent with four or more neighbors playing
$x$
is the best response for any agent with four or more neighbors playing
 $x$
.
$x$
.

Figure 2. Comparison of the correlation and independent models for a game of strategic complements.
As shown in Figure 1, there is a “critical mass” of initial strategy
 $x$
players required in order for strategy
$x$
players required in order for strategy
 $x$
to diffuse throughout the population. The existence of such a threshold is a general feature of the model for games of strategic complements. Figure 2 compares predictions from the correlation model and the independent model in a game of strategic complements for the same parameters. In this example, the critical mass is approximately .26. The middle upward bending purple curve starts with
$x$
to diffuse throughout the population. The existence of such a threshold is a general feature of the model for games of strategic complements. Figure 2 compares predictions from the correlation model and the independent model in a game of strategic complements for the same parameters. In this example, the critical mass is approximately .26. The middle upward bending purple curve starts with
 $p_x=.265$
, which is just enough above this tipping point for the
$p_x=.265$
, which is just enough above this tipping point for the
 $x$
strategy to diffuse and eventually converge to the all
$x$
strategy to diffuse and eventually converge to the all
 $x$
equilibrium. However, the green line for the independent model that starts at this same fraction of initial strategy
$x$
equilibrium. However, the green line for the independent model that starts at this same fraction of initial strategy
 $x$
players trends downward to the all
$x$
players trends downward to the all
 $y$
equilibrium. In other words, the critical mass required for strategy
$y$
equilibrium. In other words, the critical mass required for strategy
 $x$
to spread is lower in the correlation model than in the analogous model without local correlation. Because
$x$
to spread is lower in the correlation model than in the analogous model without local correlation. Because
 $\tau /k\lt \frac {1}{2}$
, the all
$\tau /k\lt \frac {1}{2}$
, the all
 $x$
equilibrium is socially preferred to the all
$x$
equilibrium is socially preferred to the all
 $y$
equilibrium. As in this example, in general, the basin of attraction for the socially preferred outcome is larger in the correlation model developed here than in the independent model. In other words, the additional individual information leads to better collective decision-making.
$y$
equilibrium. As in this example, in general, the basin of attraction for the socially preferred outcome is larger in the correlation model developed here than in the independent model. In other words, the additional individual information leads to better collective decision-making.
4.2 Strategic substitutes
We also consider games of strategic substitutes, which are particularly interesting for understanding the provision of public goods. In many cases, it may only be necessary that a public good be provided locally. For example, in the case of information provision if one person in a network neighborhood does the work of gathering and disseminating important information, then there is no incentive for others in that neighborhood to duplicate their effort. Similarly, for a parent it may only be important that parents of children at the same school volunteer to lead field trips or after school activities, and it may only be important to us that people in our neighborhood make the effort to pick up liter.
The payoff inequalities for games of strategic substitutes follow the opposite relationship as for games of strategic complements studied in the previous section:
 \begin{equation} \pi _x(k_x)-\pi _y(k_x)\leq \pi _x(k_x')-\pi _y(k_x') \end{equation}
\begin{equation} \pi _x(k_x)-\pi _y(k_x)\leq \pi _x(k_x')-\pi _y(k_x') \end{equation}
for any
 $k_x$
and
$k_x$
and
 $k_x'$
with
$k_x'$
with
 $k_x\geq k_x'$
.
$k_x\geq k_x'$
.
The best shot public goods game described above is a game of strategic substitutes.
4.2.1 Dynamics with strategic substitutes
With strategic substitutes the best response function again satisfies a threshold rule, but in this case the inequality is reversed: if
 $k_x\leq \tau$
play
$k_x\leq \tau$
play
 $x$
, if
$x$
, if
 $k_x\gt \tau$
play
$k_x\gt \tau$
play
 $y$
. The analogous versions of equations (15) and (16) are
$y$
. The analogous versions of equations (15) and (16) are
 \begin{equation} \dot {p}_x=\sum _{k_x=0}^\tau \frac {p_{y}}{N} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=\tau +1}^{k} \frac {p_x}{N} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}, \end{equation}
\begin{equation} \dot {p}_x=\sum _{k_x=0}^\tau \frac {p_{y}}{N} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=\tau +1}^{k} \frac {p_x}{N} \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}, \end{equation}
and
 \begin{equation} \dot {p}_{xx}=\sum _{k_x=0}^\tau \frac {2k_x}{kN}p_{y} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=\tau +1}^{k} \frac {2k_x}{kN}p_x \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}
\begin{equation} \dot {p}_{xx}=\sum _{k_x=0}^\tau \frac {2k_x}{kN}p_{y} \frac {k!}{k_x!k_y!}p_{x|y}^{k_x}p_{y|y}^{k_y} - \sum _{k_x=\tau +1}^{k} \frac {2k_x}{kN}p_x \frac {k!}{k_x!k_y!}p_{x|x}^{k_x}p_{y|x}^{k_y}. \end{equation}

Figure 3. The evolution of the fraction of agents playing
 $x$
over time in a game of strategic substitutes under a range of initial conditions.
$x$
over time in a game of strategic substitutes under a range of initial conditions.
As with strategic complements, equations (18) and (19) can be numerically integrated to determine the evolution of play in the population for any given initial conditions. Figure 3 plots the fraction of strategy
 $x$
players over time for a game of strategic substitutes with
$x$
players over time for a game of strategic substitutes with
 $\tau =4$
for a range of initial conditions. Unlike the strategic complements case, with strategic substitutes the long run outcome is the same regardless of the initial conditions. In general, if
$\tau =4$
for a range of initial conditions. Unlike the strategic complements case, with strategic substitutes the long run outcome is the same regardless of the initial conditions. In general, if
 $\tau \lt k/2$
, then the predicted equilibrium fraction of agents playing
$\tau \lt k/2$
, then the predicted equilibrium fraction of agents playing
 $x$
in the correlation model is lower than that predicted by the independent model, a point we return to in Section 5.
$x$
in the correlation model is lower than that predicted by the independent model, a point we return to in Section 5.
5. Local correlation
Besides the strategy frequencies over time, the model provides additional information about the correlation in neighbors’ behavior. For example, Figure 4 plots the conditional probability
 $p_{x|x}$
that a given neighbor of an agent playing
$p_{x|x}$
that a given neighbor of an agent playing
 $x$
is also playing
$x$
is also playing
 $x$
in the model for strategic substitutes (solid orange) and strategic complements (solid blue) (
$x$
in the model for strategic substitutes (solid orange) and strategic complements (solid blue) (
 $\tau =4$
in both cases).
$\tau =4$
in both cases).

Figure 4. The conditional probability
 $p_{x|x}$
from the correlation model (solid lines), and the fraction of agents playing strategy
$p_{x|x}$
from the correlation model (solid lines), and the fraction of agents playing strategy
 $x$
from an independent model (dashed lines). The blue lines are for a game of strategic complements and the orange lines are for a game of strategic substitutes.
$x$
from an independent model (dashed lines). The blue lines are for a game of strategic complements and the orange lines are for a game of strategic substitutes.
For comparison, we also examine the analogous independent network game, which corresponds to the framework developed by Galeotti et al. (Reference Galeotti, Goyal, Jackson, Vega-Redondo and Yariv2010).Footnote
6
Since the independent model assumes that neighboring agents’ strategies are independent,
 $p_x$
is the best estimate for
$p_x$
is the best estimate for
 $p_{x|x}$
available. The dashed lines in Figure 4 display the predicted fraction of agents playing strategy
$p_{x|x}$
available. The dashed lines in Figure 4 display the predicted fraction of agents playing strategy
 $x$
from the independent network game.
$x$
from the independent network game.
In the game of strategic substitutes (orange), the independent model predicts that any given agent will play strategy
 $x$
with probability .465, and regardless of their strategy, any neighbor of a given agent will also play
$x$
with probability .465, and regardless of their strategy, any neighbor of a given agent will also play
 $x$
with probability .465. The resulting probability that an agent playing
$x$
with probability .465. The resulting probability that an agent playing
 $x$
has more than four of their neighbors playing
$x$
has more than four of their neighbors playing
 $x$
is
$x$
is
 \begin{equation} \sum _{k_x=5}^{10} \frac {10!}{k_x!(10-k_x)!}.465^{k_x}(1-.465)^{10-k_x} = .534. \end{equation}
\begin{equation} \sum _{k_x=5}^{10} \frac {10!}{k_x!(10-k_x)!}.465^{k_x}(1-.465)^{10-k_x} = .534. \end{equation}
Thus, at any given time more than half of the agents playing
 $x$
would be better off playing
$x$
would be better off playing
 $y$
. If we think of playing
$y$
. If we think of playing
 $x$
as providing a public good, then the good is over provided in the independent model. The over provision results from agents’ limited information. While agents are responding optimally to the average play in the population, by chance an agent playing
$x$
as providing a public good, then the good is over provided in the independent model. The over provision results from agents’ limited information. While agents are responding optimally to the average play in the population, by chance an agent playing
 $x$
will frequently be matched with more than four other agents playing
$x$
will frequently be matched with more than four other agents playing
 $x$
.
$x$
.

Figure 5. The expected number of neighbors playing
 $x$
for an agent playing
$x$
for an agent playing
 $x$
in a game of strategic substitutes with
$x$
in a game of strategic substitutes with
 $\tau =4$
under the correlation model (purple) and the independent model (green).
$\tau =4$
under the correlation model (purple) and the independent model (green).
As the figure shows, the correlation model predicts a dissociative relationship in neighboring agents’ strategies (solid orange). The probability that a random agent plays
 $x$
is .473, but the probability that the neighbor of an agent playing
$x$
is .473, but the probability that the neighbor of an agent playing
 $x$
also plays
$x$
also plays
 $x$
at equilibrium is only .230. The probability that an agent playing
$x$
at equilibrium is only .230. The probability that an agent playing
 $x$
has more than four neighbors playing
$x$
has more than four neighbors playing
 $x$
is only
$x$
is only
 \begin{equation} \sum _{k_x=5}^{10} \frac {10!}{k_x!(10-k_x)!}.230^{k_x}(1-.230)^{10-k_x} = .057. \end{equation}
\begin{equation} \sum _{k_x=5}^{10} \frac {10!}{k_x!(10-k_x)!}.230^{k_x}(1-.230)^{10-k_x} = .057. \end{equation}
Agents in the correlation model fare better because they take their own behavior into account when calculating the expected behavior of their neighbors. For example, consider the case of information provision. If I have provided information to my friends in the past, then I know that in the future my friends are less likely to seek out information because they may count on free riding off of me. Therefore, I should be more likely to continue to provide information because I know that my friends are unlikely to provide it. Figure 5 provides a second illustration of this point by plotting the expected number of neighbors playing strategy
 $x$
for an agent playing strategy
$x$
for an agent playing strategy
 $x$
under both the correlation (purple) and independent (green) models. The dashed horizontal line at three indicates the optimal number of neighbors. On average, in the independent model agents playing
$x$
under both the correlation (purple) and independent (green) models. The dashed horizontal line at three indicates the optimal number of neighbors. On average, in the independent model agents playing
 $x$
can expect to have two more neighbors playing
$x$
can expect to have two more neighbors playing
 $x$
than they would prefer, while the equilibrium in the correlation model is very near the optimum.
$x$
than they would prefer, while the equilibrium in the correlation model is very near the optimum.
With strategic complements (blue lines in Figure 4), players coordinate locally. Ultimately, the independent model and our model make similar predictions: both models predict that nearly all of the agents play
 $x$
and therefore the probability that a neighbor of an agent playing
$x$
and therefore the probability that a neighbor of an agent playing
 $x$
also plays
$x$
also plays
 $x$
approaches one. However, our model results in rapid local coordination as clusters of agents playing
$x$
approaches one. However, our model results in rapid local coordination as clusters of agents playing
 $x$
form and then expand.
$x$
form and then expand.
6. Clustering
Up to this point we have always made the conditionally independent neighbors assumption; however, many empirical social networks exhibit significant clustering (Newman and Park, Reference Newman and Park2003; Watts, Reference Watts2004), casting doubt on this assumption. In this section, we describe a refinement to the model that incorporates clustering. We measure clustering using the well-known clustering coefficient:
 \begin{equation} C=\frac {(\textrm {number of closed paths of length two})}{(\textrm {number of paths of length two})} \end{equation}
\begin{equation} C=\frac {(\textrm {number of closed paths of length two})}{(\textrm {number of paths of length two})} \end{equation}
(p. 184 Newman, Reference Newman2018). The clustering coefficient captures the probability that any two neighbors of a given node are themselves neighbors.
When
 $C$
is nonzero, we expect that some neighboring nodes are neighbors of each other, and thus their strategies are not independent. Consider three nodes, a central node
$C$
is nonzero, we expect that some neighboring nodes are neighbors of each other, and thus their strategies are not independent. Consider three nodes, a central node
 $i$
with two neighbors,
$i$
with two neighbors,
 $j$
and
$j$
and
 $k$
. Let
$k$
. Let
 $p_{\alpha |\beta \gamma }$
denote the probability that
$p_{\alpha |\beta \gamma }$
denote the probability that
 $j$
uses strategy
$j$
uses strategy
 $\alpha$
when
$\alpha$
when
 $i$
and
$i$
and
 $k$
play strategies
$k$
play strategies
 $\beta$
and
$\beta$
and
 $\gamma$
, respectively. We can split this probability into two components, the probability when
$\gamma$
, respectively. We can split this probability into two components, the probability when
 $j$
and
$j$
and
 $k$
are connected forming a closed triangle,
$k$
are connected forming a closed triangle,
 $p_{\alpha |\beta \gamma }^{\bigtriangledown }$
, and the probability when
$p_{\alpha |\beta \gamma }^{\bigtriangledown }$
, and the probability when
 $j$
and
$j$
and
 $k$
are not connected,
$k$
are not connected,
 $p_{\alpha |\beta \gamma }^{\vee }$
. Then
$p_{\alpha |\beta \gamma }^{\vee }$
. Then
 \begin{equation} p_{\alpha |\beta \gamma }=C p_{\alpha |\beta \gamma }^{\bigtriangledown } + (1-C) p_{\alpha |\beta \gamma }^{\vee }. \end{equation}
\begin{equation} p_{\alpha |\beta \gamma }=C p_{\alpha |\beta \gamma }^{\bigtriangledown } + (1-C) p_{\alpha |\beta \gamma }^{\vee }. \end{equation}
The probability
 $p_{\alpha |\beta \gamma }^{\vee }$
is the easier of the two to deal with. Since in this case
$p_{\alpha |\beta \gamma }^{\vee }$
is the easier of the two to deal with. Since in this case
 $j$
and
$j$
and
 $k$
are not connected, we assume that their strategies are independent conditional on the strategy of
$k$
are not connected, we assume that their strategies are independent conditional on the strategy of
 $i$
, and thus
$i$
, and thus
 $p_{\alpha |\beta \gamma }^{\vee }=p_{\alpha |\beta }$
. To estimate
$p_{\alpha |\beta \gamma }^{\vee }=p_{\alpha |\beta }$
. To estimate
 $p_{\alpha |\beta \gamma }^{\bigtriangledown }$
, we use a strategy suggested by Morris (Reference Morris1997) (see also Rand, Reference Rand and McGlade1999). First, we assume that
$p_{\alpha |\beta \gamma }^{\bigtriangledown }$
, we use a strategy suggested by Morris (Reference Morris1997) (see also Rand, Reference Rand and McGlade1999). First, we assume that
 \begin{equation} \frac {p_{\alpha |\beta \gamma }^{\bigtriangledown }}{p_{\alpha |\cdot \gamma }^{\bigtriangledown }}\cong \frac {p_{\alpha |\beta \gamma }^{\vee }}{p_{\alpha |\cdot \gamma }^{\vee }}. \end{equation}
\begin{equation} \frac {p_{\alpha |\beta \gamma }^{\bigtriangledown }}{p_{\alpha |\cdot \gamma }^{\bigtriangledown }}\cong \frac {p_{\alpha |\beta \gamma }^{\vee }}{p_{\alpha |\cdot \gamma }^{\vee }}. \end{equation}
The idea behind this assumption is that the strategy of
 $i$
, given the strategies of
$i$
, given the strategies of
 $j$
and
$j$
and
 $k$
, should not be affected much by whether
$k$
, should not be affected much by whether
 $j$
and
$j$
and
 $k$
are also neighbors. In the right-hand side denominator, since
$k$
are also neighbors. In the right-hand side denominator, since
 $j$
and
$j$
and
 $k$
are not connected, we should have
$k$
are not connected, we should have
 $p_{\alpha |\cdot \gamma }^{\vee }=p_{\alpha |\cdot }=p_{\alpha }.$
For the left-hand side denominator, the probability that
$p_{\alpha |\cdot \gamma }^{\vee }=p_{\alpha |\cdot }=p_{\alpha }.$
For the left-hand side denominator, the probability that
 $j$
uses strategy
$j$
uses strategy
 $\alpha$
given that
$\alpha$
given that
 $j$
is connected to
$j$
is connected to
 $i$
using an unknown strategy and
$i$
using an unknown strategy and
 $k$
using strategy
$k$
using strategy
 $\gamma$
is simply
$\gamma$
is simply
 $p_{\alpha |\gamma }$
. Substituting into equation (24) we obtain the approximation
$p_{\alpha |\gamma }$
. Substituting into equation (24) we obtain the approximation
 \begin{equation} p_{\alpha |\beta \gamma }^{\bigtriangledown } \cong \frac {p_{\alpha |\beta }p_{\alpha |\gamma }}{p_\alpha }. \end{equation}
\begin{equation} p_{\alpha |\beta \gamma }^{\bigtriangledown } \cong \frac {p_{\alpha |\beta }p_{\alpha |\gamma }}{p_\alpha }. \end{equation}
Finally, substituting back into equation (23) gives
 \begin{equation} p_{\alpha |\beta \gamma }\cong C\left (\frac {p_{\alpha |\beta }p_{\alpha |\gamma }}{p_\alpha }\right ) + (1-C) p_{\alpha |\beta }. \end{equation}
\begin{equation} p_{\alpha |\beta \gamma }\cong C\left (\frac {p_{\alpha |\beta }p_{\alpha |\gamma }}{p_\alpha }\right ) + (1-C) p_{\alpha |\beta }. \end{equation}
To see how we incorporate this new conditional probability into the dynamic equations (8) and (11), it helps to rewrite the equations slightly. We start with equation (11) for
 $\dot {p}_{xx}$
. Rather than thinking of randomly selecting a node to update, we could randomly select an edge and then choose a node at one end of that edge (since all nodes have the same degree, these are equivalent). The probability
$\dot {p}_{xx}$
. Rather than thinking of randomly selecting a node to update, we could randomly select an edge and then choose a node at one end of that edge (since all nodes have the same degree, these are equivalent). The probability
 $p_{xx}$
can only increase if we select the
$p_{xx}$
can only increase if we select the
 $y$
end of either an
$y$
end of either an
 $xy$
edge or a
$xy$
edge or a
 $yx$
edge, which occurs with probability
$yx$
edge, which occurs with probability
 $\frac {1}{2}(p_{xy}+p_{yx})=\frac {1}{2}(2p_{xy})=p_{xy}.$
$\frac {1}{2}(p_{xy}+p_{yx})=\frac {1}{2}(2p_{xy})=p_{xy}.$
Call the selected agent
 $i$
and the opposite end of the selected edge
$i$
and the opposite end of the selected edge
 $j$
. Agent
$j$
. Agent
 $i$
will switch to playing
$i$
will switch to playing
 $x$
if
$x$
if
 $k_x\in BR^{-1}(x)$
. Since we already know that
$k_x\in BR^{-1}(x)$
. Since we already know that
 $j$
is playing
$j$
is playing
 $x$
, the probability that
$x$
, the probability that
 $i$
has exactly
$i$
has exactly
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
is equal to the probability that
$x$
is equal to the probability that
 $i$
has
$i$
has
 $k_x-1$
additional neighbors playing
$k_x-1$
additional neighbors playing
 $x$
. The probability that any one of
$x$
. The probability that any one of
 $i$
’s neighbors (besides
$i$
’s neighbors (besides
 $j$
) plays
$j$
) plays
 $x$
is
$x$
is
 $p_{x|yx}$
. Now, rather than the CIN assumption, we assume that
$p_{x|yx}$
. Now, rather than the CIN assumption, we assume that
 $i$
’s neighbors are independent conditional on
$i$
’s neighbors are independent conditional on
 $i$
and
$i$
and
 $j$
’s strategies. Thus, the probability that
$j$
’s strategies. Thus, the probability that
 $i$
has
$i$
has
 $k_x$
neighbors playing
$k_x$
neighbors playing
 $x$
and
$x$
and
 $k_y=k-k_x$
neighbors playing
$k_y=k-k_x$
neighbors playing
 $y$
is
$y$
is
 \begin{equation} \frac {(k-1)!}{(k_x-1)!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}. \end{equation}
\begin{equation} \frac {(k-1)!}{(k_x-1)!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}. \end{equation}
If
 $i$
changes from
$i$
changes from
 $y$
to
$y$
to
 $x$
then
$x$
then
 $p_{xx}$
increases by
$p_{xx}$
increases by
 $2/N$
. Performing a similar calculation for decreases in
$2/N$
. Performing a similar calculation for decreases in
 $p_{xx}$
we obtain
$p_{xx}$
we obtain
 \begin{align} \dot {p}_{xx}&=\sum _{k_x\in BR^{-1}(x)}\frac {2}{N}p_{xy}\frac {(k-1)!}{(k_x-1)!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}-\sum _{k_x\in BR^{-1}(y)}\frac {2}{N}p_{xx}\frac {(k-1)!}{(k_x-1)!k_y!}p_{x|xx}^{k_x-1}p_{y|xx}^{k_y}\\[-6pt]\nonumber \end{align}
\begin{align} \dot {p}_{xx}&=\sum _{k_x\in BR^{-1}(x)}\frac {2}{N}p_{xy}\frac {(k-1)!}{(k_x-1)!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}-\sum _{k_x\in BR^{-1}(y)}\frac {2}{N}p_{xx}\frac {(k-1)!}{(k_x-1)!k_y!}p_{x|xx}^{k_x-1}p_{y|xx}^{k_y}\\[-6pt]\nonumber \end{align}
 \begin{align} &=\sum _{k_x\in BR^{-1}(x)}\frac {2k_x}{kN}p_{xy}\frac {k!}{k_x!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}-\sum _{k_x\in BR^{-1}(y)}\frac {2k_x}{kN}p_{xx}\frac {k!}{k_x!k_y!}p_{x|xx}^{k_x-1}p_{y|xx}^{k_y}. \end{align}
\begin{align} &=\sum _{k_x\in BR^{-1}(x)}\frac {2k_x}{kN}p_{xy}\frac {k!}{k_x!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}-\sum _{k_x\in BR^{-1}(y)}\frac {2k_x}{kN}p_{xx}\frac {k!}{k_x!k_y!}p_{x|xx}^{k_x-1}p_{y|xx}^{k_y}. \end{align}
Under the CIN assumption this equation is equivalent to (11). To see this, note that under CIN
 $p_{\alpha |\beta \gamma }$
is replaced by
$p_{\alpha |\beta \gamma }$
is replaced by
 $p_{\alpha |\beta }$
giving
$p_{\alpha |\beta }$
giving
 \begin{equation} \dot {p}_{xx}=\sum _{k_x\in BR^{-1}(x)}\frac {2k_x}{kN}p_{xy}\frac {k!}{k_x!k_y!}p_{x|y}^{k_x-1}p_{y|y}^{k_y}-\sum _{k_x\in BR^{-1}(y)}\frac {2k_x}{kN}p_{xx}\frac {k!}{k_x!k_y!}p_{x|x}^{k_x-1}p_{y|x}^{k_y}. \end{equation}
\begin{equation} \dot {p}_{xx}=\sum _{k_x\in BR^{-1}(x)}\frac {2k_x}{kN}p_{xy}\frac {k!}{k_x!k_y!}p_{x|y}^{k_x-1}p_{y|y}^{k_y}-\sum _{k_x\in BR^{-1}(y)}\frac {2k_x}{kN}p_{xx}\frac {k!}{k_x!k_y!}p_{x|x}^{k_x-1}p_{y|x}^{k_y}. \end{equation}
Substituting
 $p_{xy}=p_{x|y}p_y$
and
$p_{xy}=p_{x|y}p_y$
and
 $p_{xx}=p_{x|x}p_x$
, we recover (11).
$p_{xx}=p_{x|x}p_x$
, we recover (11).
Now, instead of replacing
 $p_{\alpha |\beta \gamma }$
by
$p_{\alpha |\beta \gamma }$
by
 $p_{\alpha |\beta }$
, we use (26) for
$p_{\alpha |\beta }$
, we use (26) for
 $p_{\alpha |\beta \gamma }$
in equation (29). A similar argument applies to
$p_{\alpha |\beta \gamma }$
in equation (29). A similar argument applies to
 $\dot {p}_x$
giving
$\dot {p}_x$
giving
 \begin{align} \dot {p}_x&=\sum _{k_x\in BR^{-1}(x)}\frac {k_yp_{yy}}{kN}\frac {k!}{k_x!k_y!}p_{x|yy}^{k_x}p_{y|yy}^{k_y-1}\\[-6pt]\nonumber \end{align}
\begin{align} \dot {p}_x&=\sum _{k_x\in BR^{-1}(x)}\frac {k_yp_{yy}}{kN}\frac {k!}{k_x!k_y!}p_{x|yy}^{k_x}p_{y|yy}^{k_y-1}\\[-6pt]\nonumber \end{align}
 \begin{align} &-\sum _{k_x\in BR^{-1}(y)}\frac {k_yp_{xy}}{kN}\frac {k!}{k_x!k_y!}p_{x|xy}^{k_x}p_{y|xy}^{k_y-1}\\[-6pt]\nonumber \end{align}
\begin{align} &-\sum _{k_x\in BR^{-1}(y)}\frac {k_yp_{xy}}{kN}\frac {k!}{k_x!k_y!}p_{x|xy}^{k_x}p_{y|xy}^{k_y-1}\\[-6pt]\nonumber \end{align}
 \begin{align} &+\sum _{k_x\in BR^{-1}(x)}\frac {k_xp_{xy}}{kN}\frac {k!}{k_x!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}\\[-6pt]\nonumber \end{align}
\begin{align} &+\sum _{k_x\in BR^{-1}(x)}\frac {k_xp_{xy}}{kN}\frac {k!}{k_x!k_y!}p_{x|yx}^{k_x-1}p_{y|yx}^{k_y}\\[-6pt]\nonumber \end{align}
 \begin{align} &-\sum _{k_x\in BR^{-1}(y)}\frac {k_xp_{xx}}{kN}\frac {k!}{k_x!k_y!}p_{x|xx}^{k_x-1}p_{y|xx}^{k_y}, \end{align}
\begin{align} &-\sum _{k_x\in BR^{-1}(y)}\frac {k_xp_{xx}}{kN}\frac {k!}{k_x!k_y!}p_{x|xx}^{k_x-1}p_{y|xx}^{k_y}, \end{align}
where again (26) is used for the
 $p_{\alpha |\beta \gamma }$
terms. When
$p_{\alpha |\beta \gamma }$
terms. When
 $C=0$
, the equations again collapse to recover the original differential equation for
$C=0$
, the equations again collapse to recover the original differential equation for
 $\dot {p}_x$
shown in equation (8).
$\dot {p}_x$
shown in equation (8).

Figure 6. The effect of clustering under strategic substitutes.

Figure 7. The effect of clustering under strategic complements.
Figure 6 depicts the effect of clustering under strategic substitutes for a variety of initial conditions. In all cases, when the network is highly clustered, fewer agents play strategy
 $x$
. In the case of public goods provision, this means that more agents play the role of the public good provider in an unclustered network than in a highly clustered network. Clustering allows agents to coordinate locally, ensuring that no more individuals provide the public good than necessary.
$x$
. In the case of public goods provision, this means that more agents play the role of the public good provider in an unclustered network than in a highly clustered network. Clustering allows agents to coordinate locally, ensuring that no more individuals provide the public good than necessary.
Figure 7 depicts the effect of clustering under strategic complements. Here, we see that clustering allows for stable “shared market” equilibria where some agents play
 $x$
while others play
$x$
while others play
 $y$
that do not exist for the same game of strategic complements played in an unclustered network. Here again, clustering allows agents to coordinate locally—so there can be pockets of mostly
$y$
that do not exist for the same game of strategic complements played in an unclustered network. Here again, clustering allows agents to coordinate locally—so there can be pockets of mostly
 $y$
players even when outside of these pockets most of the network plays
$y$
players even when outside of these pockets most of the network plays
 $x$
. In this case since the best response threshold
$x$
. In this case since the best response threshold
 $\tau =4$
is less than half of each agents’ total number of neighbors,
$\tau =4$
is less than half of each agents’ total number of neighbors,
 $k=10$
, the all
$k=10$
, the all
 $x$
equilibrium is socially preferred to the all
$x$
equilibrium is socially preferred to the all
 $y$
equilibrium. These shared market solutions reduce overall welfare compared to the all
$y$
equilibrium. These shared market solutions reduce overall welfare compared to the all
 $x$
equilibrium because the people in these
$x$
equilibrium because the people in these
 $y$
-playing clusters would be better off if everyone switched to playing
$y$
-playing clusters would be better off if everyone switched to playing
 $x$
. If we think of strategy
$x$
. If we think of strategy
 $x$
as a new technology spreading through the population, even with high initial levels of technology
$x$
as a new technology spreading through the population, even with high initial levels of technology
 $x$
adoption, network clustering prevents that beneficial innovation from reaching some niche populations. On the other hand, for low initial levels of technology
$x$
adoption, network clustering prevents that beneficial innovation from reaching some niche populations. On the other hand, for low initial levels of technology
 $x$
adoption there are benefits to clustering because it allows pockets of technology
$x$
adoption there are benefits to clustering because it allows pockets of technology
 $x$
users to survive despite the dominance of the inferior incumbent technology
$x$
users to survive despite the dominance of the inferior incumbent technology
 $y$
. By maintaining diversity, these clustered niches could serve as incubators for technologies to improve without being wiped out by more popular competitors.
$y$
. By maintaining diversity, these clustered niches could serve as incubators for technologies to improve without being wiped out by more popular competitors.
7. Conclusion
Local correlation is likely to arise in many empirical situations where individuals’ behavior is influenced by that of their social contacts. This paper develops a model of games played in a social network that takes local correlation into account. The model provides a more realistic representation of many empirical situations than previous frameworks and also provides predictions about local correlation that have been unavailable in previous models. For example, we find that agents’ strategies tend to be locally associative in games of strategic substitutes and locally dissociative in games of strategic complements.
We also extend the framework to account for network clustering. In the case of strategic substitutes, we demonstrate that clustering reduces the number of agents playing the role of provider of a public good at equilibrium. In the case of strategic complements, we find that clustering can lead to market sharing.
Several simplifying assumptions are made to make the analysis more tractable. In particular, we have only considered binary action games, and we have assumed that all agents have the same degree. Examining richer action spaces and general degree distributions within the framework are important directions for future work.
Funding statement
This research was partially supported by the UCLA Council on Research Research Allowance Program.
Competing interests
The author declares no competing interests.
Appendix A. Imitation, evolutionary dynamics, and analytic solutions
The pairs of differential equations (15)-(16) and (18)-(19) can be numerically integrated to solve for the fraction of agents playing
 $x$
or
$x$
or
 $y$
over time as shown in sections 4.1.2 and 4.2.1. The results under one set of parameters for a variety of initial conditions depicted in Figures 1 and 3 illustrate the typical dynamics: in games of strategic complements two winner-take-all equilibria are separated by an unstable equilibrium, and in games of strategic substitutes agents converge to a unique stable equilibrium regardless of initial conditions.
$y$
over time as shown in sections 4.1.2 and 4.2.1. The results under one set of parameters for a variety of initial conditions depicted in Figures 1 and 3 illustrate the typical dynamics: in games of strategic complements two winner-take-all equilibria are separated by an unstable equilibrium, and in games of strategic substitutes agents converge to a unique stable equilibrium regardless of initial conditions.
Solving these equations for a wide range of parameters indicates that this behavior is generic, but analytic solutions for the equilibria of (15)-(16) and (18)-(19) are unavailable to confirm this. However, analytic solutions can be obtained under alternative assumptions regarding how agents update their behavior. One such alternative is to assume that agents imitate the strategies of successful neighbors. Similar imitation dynamics have been modeled by Vega-Redondo (Reference Vega-Redondo1997), Schlag (Reference Schlag1998), Apesteguia et al. (Reference Apesteguia, Huck and Oechssler2007), and Choi et al. (Reference Choi, Goyal, Guo and Moisan2024). As shown by Apesteguia et al. (Reference Apesteguia, Huck and Oechssler2007), subtle changes in the informational assumptions of such models can have substantial effects on equilibrium behavior. Here, we assume that at each time an individual,
 $i$
, is chosen at random to update their behavior and then chooses their strategy in the next period with the probability of choosing a given strategy proportional to the average payoff of that strategy among all of
$i$
, is chosen at random to update their behavior and then chooses their strategy in the next period with the probability of choosing a given strategy proportional to the average payoff of that strategy among all of
 $i$
’s neighbors. We refer to this rule as imitation proportional to payoffs (IPP). Choi et al. (Reference Choi, Goyal, Guo and Moisan2024) show that equilibrium play using a similar imitation rule better fits the observed relationship between centrality and player strategies in an experimental setting than predictions from best response dynamics.
$i$
’s neighbors. We refer to this rule as imitation proportional to payoffs (IPP). Choi et al. (Reference Choi, Goyal, Guo and Moisan2024) show that equilibrium play using a similar imitation rule better fits the observed relationship between centrality and player strategies in an experimental setting than predictions from best response dynamics.
Under the assumptions of IPP, we can apply results from Morris (Reference Morris1997) to find analytical solutions for pairwise binary games as described in Example 1 above with payoffs as shown in Table 1.
Specifically, the pairwise binary game described in Example 1 with payoffs as shown in Table 1 is equivalent to the pairwise binary game with “death-birth” evolutionary dynamics described in Section 2.2 of Morris (Reference Morris1997). Morris solves the corresponding differential equations with the computer algebra system MAPLE. Translating those results to our notation, there are three potential equilibria. The first is the trivial solution where
 $p_{xy}=0$
and
$p_{xy}=0$
and
 $p_{xx}+p_{yy}=1$
. In this case, agents only neighbor other individuals playing their same strategy, and so there is no one playing the opposite strategy to imitate.
$p_{xx}+p_{yy}=1$
. In this case, agents only neighbor other individuals playing their same strategy, and so there is no one playing the opposite strategy to imitate.
The two non-trivial solutions are:
 \begin{align} p_{xx}&=\frac {bk(d(k-1)+c)}{(k-1)(k(ac+bd-2ad)-2(a-b)(c-d))}\\[-6pt]\nonumber \end{align}
\begin{align} p_{xx}&=\frac {bk(d(k-1)+c)}{(k-1)(k(ac+bd-2ad)-2(a-b)(c-d))}\\[-6pt]\nonumber \end{align}
 \begin{align} p_{yy}&=\frac {ck(a(k-1)+b)}{(k-1)(k(ac+bd-2ad)-2(a-b)(c-d))}\\[-6pt]\nonumber \end{align}
\begin{align} p_{yy}&=\frac {ck(a(k-1)+b)}{(k-1)(k(ac+bd-2ad)-2(a-b)(c-d))}\\[-6pt]\nonumber \end{align}
 \begin{align} p_{xy}&=\frac {-(a(k-1)+b)(d(k-1)+c)}{(k-1)(k(ac+bd-2ad)-2(a-b)(c-d))}, \end{align}
\begin{align} p_{xy}&=\frac {-(a(k-1)+b)(d(k-1)+c)}{(k-1)(k(ac+bd-2ad)-2(a-b)(c-d))}, \end{align}
and
 \begin{align} p_{xx}&=\frac {k(d-b)((d-b)(k-1)-(a-c))}{(k-1)(k-2)(a-c+d-b)^2}\\[-6pt]\nonumber \end{align}
\begin{align} p_{xx}&=\frac {k(d-b)((d-b)(k-1)-(a-c))}{(k-1)(k-2)(a-c+d-b)^2}\\[-6pt]\nonumber \end{align}
 \begin{align} p_{yy}&=\frac {k(a-c)((a-c)(k-1)-(d-b))}{(k-1)(k-2)(a-c+d-b)^2}\\[-6pt]\nonumber \end{align}
\begin{align} p_{yy}&=\frac {k(a-c)((a-c)(k-1)-(d-b))}{(k-1)(k-2)(a-c+d-b)^2}\\[-6pt]\nonumber \end{align}
 \begin{align} p_{xy}&=\frac {((a-c)(k-1)-(d-b))((d-b)(k-1)-(a-c))}{(k-1)(k-2)(a-c+d-b)^2}, \end{align}
\begin{align} p_{xy}&=\frac {((a-c)(k-1)-(d-b))((d-b)(k-1)-(a-c))}{(k-1)(k-2)(a-c+d-b)^2}, \end{align}
where
 $N$
has been set to one to simplify the equations. (See section 2.6.1 of Morris (Reference Morris1997) for further details.)
$N$
has been set to one to simplify the equations. (See section 2.6.1 of Morris (Reference Morris1997) for further details.)
The first non-trivial solution is a special case: if
 $b=c=0$
then there is an unstable equilibrium with
$b=c=0$
then there is an unstable equilibrium with
 $p_{xx}=p_{yy}=0$
and
$p_{xx}=p_{yy}=0$
and
 $p_{xy}=1/2$
. In this case, agents prefer to coordinate with their neighbors, but exactly half their neighbors play
$p_{xy}=1/2$
. In this case, agents prefer to coordinate with their neighbors, but exactly half their neighbors play
 $x$
, and half play
$x$
, and half play
 $y$
, so it’s not clear which strategy to coordinate on. The eigenvalues of the Jacobian are both positive, so the solution is unstable; any deviation that breaks the symmetry will tip the system to an all
$y$
, so it’s not clear which strategy to coordinate on. The eigenvalues of the Jacobian are both positive, so the solution is unstable; any deviation that breaks the symmetry will tip the system to an all
 $x$
or all
$x$
or all
 $y$
equilibrium.
$y$
equilibrium.
The second non-trivial solution is an unsegregated equilibrium in which some agents play
 $x$
while others play
$x$
while others play
 $y$
, the stability of which depends on the sign of
$y$
, the stability of which depends on the sign of
 $a-c$
and
$a-c$
and
 $d-b$
. When both
$d-b$
. When both
 $a-c$
and
$a-c$
and
 $d-b$
are positive, the unsegregated coexistence equilibrium is an unstable saddle point, but both of the winner-take-all equilibria are locally stable. In this case, it must be that
$d-b$
are positive, the unsegregated coexistence equilibrium is an unstable saddle point, but both of the winner-take-all equilibria are locally stable. In this case, it must be that
 $a-b-c+d\gt 0$
, so the game is a game of strategic complements. Thus, the analytic finding of two stable winner-take-all equilibria separated by an unstable tipping point under IPP dynamics matches the numerical findings for the same class of games under best response dynamics. When both
$a-b-c+d\gt 0$
, so the game is a game of strategic complements. Thus, the analytic finding of two stable winner-take-all equilibria separated by an unstable tipping point under IPP dynamics matches the numerical findings for the same class of games under best response dynamics. When both
 $a-c$
and
$a-c$
and
 $d-b$
are negative, there is a stable unsegregated coexistence equilibrium. In this case, since
$d-b$
are negative, there is a stable unsegregated coexistence equilibrium. In this case, since
 $a-b-c+d$
must be negative, we have a game of strategic substitutes, and again the equilibrium structure under IPP dynamics matches our numerical findings when agents best respond.
$a-b-c+d$
must be negative, we have a game of strategic substitutes, and again the equilibrium structure under IPP dynamics matches our numerical findings when agents best respond.
Appendix B. Simulations
B.1 Model as approximation
Throughout this article we discuss the CIN assumption and, later, the assumption regarding the effect of network clustering in equation (26), as capturing limits on agents’ information regarding the identities or play of their neighbors. Alternatively, one could interpret the model as an approximation to agents updating in a fixed network with full knowledge of the actions of their direct network neighbors. This approximation interpretation raises the question of how closely our theoretical model matches the dynamics of such a population. In this appendix, we compare several of the numeric results from the main text with simulations in which agents in a fixed network best respond to the current play of their network neighbors.

Figure 8. Comparison of the correlation and independent models for a game of strategic complements with simulation results.
Figure 8 reproduces Figure 2, which compares the correlation and independent models for a game of strategic complements, along with average results from 500 simulation runs. (Agent-based simulations were implemented in R version 4.5.0 (R Core Team, 2025). Simulation code was written with AI assistance from ChatGPT-5 (OpenAI, 2025). All simulation code is available from the author upon request.) In each simulation run, 1000 agents are connected by a randomly selected configuration model network in which each agent has degree ten. (The configuration model is a standard method for generating random networks with a given degree sequence. See Newman (Reference Newman2018) for details.) A random subset of agents is chosen to initially play strategy
 $x$
. At each time step, a random agent is selected to update their strategy by best responding to the current play of their neighbors. To match the continuous dynamics, the simulation is modeled as a Poisson process with constant rate one, so inter-arrival times are drawn from an exponential distribution with mean one. As the figure illustrates, viewed from this perspective, the correlation model provides a more accurate approximation of the simulation dynamics than the independent model.
$x$
. At each time step, a random agent is selected to update their strategy by best responding to the current play of their neighbors. To match the continuous dynamics, the simulation is modeled as a Poisson process with constant rate one, so inter-arrival times are drawn from an exponential distribution with mean one. As the figure illustrates, viewed from this perspective, the correlation model provides a more accurate approximation of the simulation dynamics than the independent model.

Figure 9. The expected number of neighbors playing
 $x$
for an agent playing
$x$
for an agent playing
 $x$
in a game of strategic substitutes with
$x$
in a game of strategic substitutes with
 $\tau =4$
under the correlation model (purple) and the independent model (green) along with simulation results (black with x).
$\tau =4$
under the correlation model (purple) and the independent model (green) along with simulation results (black with x).
Figure 9 reproduces Figure 5, which depicts the expected number of neighbors playing
 $x$
for an agent playing
$x$
for an agent playing
 $x$
in a game of strategic substitutes under both the correlation model (purple) and the independent model (green), along with average results from 500 simulation runs. Again, simulation results match the correlation model much more closely than the independent model.
$x$
in a game of strategic substitutes under both the correlation model (purple) and the independent model (green), along with average results from 500 simulation runs. Again, simulation results match the correlation model much more closely than the independent model.

Figure 10. Simulation results for the effect of clustering under strategic substitutes.
B.2 Validation of clustering results
We can also use simulations to validate the predicted effect of clustering on equilibria. Figure 6 shows that the predicted fraction of agents playing strategy
 $x$
in a game of strategic substitutes with average degree ten and
$x$
in a game of strategic substitutes with average degree ten and
 $\tau =4$
is lower in a more clustered network.
$\tau =4$
is lower in a more clustered network.
To test this prediction we again ran 500 simulations for each initial fraction of agents employing strategy
 $x$
, but now, for each simulation, we randomly generated a low clustering network and a higher clustering network using a generalization of the configuration model to clustered networks proposed by Newman (Reference Newman2009). The average clustering coefficient in the random low clustering networks was 0.008 and the average clustering coefficient in the random high clustering networks was 0.118. The results are shown in Figure 10. The simulation results confirm the model prediction: the long run fraction of agents playing strategy
$x$
, but now, for each simulation, we randomly generated a low clustering network and a higher clustering network using a generalization of the configuration model to clustered networks proposed by Newman (Reference Newman2009). The average clustering coefficient in the random low clustering networks was 0.008 and the average clustering coefficient in the random high clustering networks was 0.118. The results are shown in Figure 10. The simulation results confirm the model prediction: the long run fraction of agents playing strategy
 $x$
is lower in the high clustering network.
$x$
is lower in the high clustering network.

Figure 11. Theoretical predictions and simulation results for the effect of clustering under strategic complements.
To validate the clustering results for strategic complements shown in Figure 7, we ran a similar set of simulations; however, the maximum level of clustering generated by the Newman (Reference Newman2009) clustered configuration model networks was too low to support the shared market outcomes shown in Figure 7. To generate networks with a higher level of clustering, we used a degree ten ring lattice (Jackson, Reference Jackson2008, p. 80), which has a clustering coefficient of 2/3. Figure 11 shows simulation results from the ring lattice (high clustering) and randomly generated configuration model networks (low clustering), alongside the theory predictions for the same levels of network clustering. The theory is less accurate for the high clustering networks, particularly with high initial fractions of
 $x$
agents; however, qualitatively the patterns are similar: in the lower clustering network, agents converge to one of the two winner-take-all equilibria, but in the high clustering network, shared market equilibria emerge.
$x$
agents; however, qualitatively the patterns are similar: in the lower clustering network, agents converge to one of the two winner-take-all equilibria, but in the high clustering network, shared market equilibria emerge.
It is important to note that while the ring lattice used here does have a higher clustering coefficient than the configuration model networks while maintaining the constant degree assumption, it introduces other structural features that could account for variations in the simulation results. This highlights one of the challenges of drawing general conclusions from network simulations (and one of the corresponding benefits of analytic models): it is difficult to choose an appropriate network generation model that allows for controlled variations in one network feature without impacting other, potentially confounding, network characteristics.
B.3 The effect of degree heterogeneity
The theoretical model in the main text only considers networks in which all agents have the same degree. Here, we briefly consider the potential impact of this assumption by comparing the model results with simulations in networks with alternative degree distributions.

Figure 12. Theoretical predictions in a regular network compared to simulation results in a network with a Poisson degree distribution under strategic complements.
Figure 12 compares the model results with strategic complements from a network in which each agent has degree ten to mean results from 500 simulations in configuration model networks with Poisson degree distributions with average degree ten. As we would expect, the theoretical predictions in the regular network do not perfectly match the simulation results from networks with heterogenous degree distributions. The effect of degree heterogeneity is inconsistent; sometimes more agents choose strategy
 $x$
in the heterogenous network, other times fewer do. However, both network types result in the overall pattern of two winner-take-all equilibria separated by a “critical mass” unstable equilibria. It would be interesting to explore how this critical mass depends on degree heterogeniety, for example, under second-order stochastic dominance shifts in the degree distribution, as has been explored for other diffusion models elsewhere (Jackson and Rogers, Reference Jackson and Rogers2007; Jackson and Yariv, Reference Jackson and Yariv2007; Lamberson, Reference Lamberson2011). We leave this question for future research.
$x$
in the heterogenous network, other times fewer do. However, both network types result in the overall pattern of two winner-take-all equilibria separated by a “critical mass” unstable equilibria. It would be interesting to explore how this critical mass depends on degree heterogeniety, for example, under second-order stochastic dominance shifts in the degree distribution, as has been explored for other diffusion models elsewhere (Jackson and Rogers, Reference Jackson and Rogers2007; Jackson and Yariv, Reference Jackson and Yariv2007; Lamberson, Reference Lamberson2011). We leave this question for future research.

Figure 13. Theoretical predictions in a regular network compared to simulation results in a network with a Poisson degree distribution under strategic substitutes.
Figure 13 makes a similar comparison with strategic substitutes. Here the results are more clear: degree heterogeneity leads a greater fraction of agents to play strategy
 $x$
. Again, in future research it would be interesting to test if this observation holds more generally.
$x$
. Again, in future research it would be interesting to test if this observation holds more generally.





























 Open access
Open access