



It is prohibitively expensive to resolve all relevant scales of turbulence for industrially relevant flows. Even with increasing computational capacity, Kolmogorov microscale-resolving techniques such as direct numerical simulation (DNS) will be out of reach for decades (Slotnick et al. Reference Slotnick, Khodadoust, Alonso, Darmofal, Gropp, Lurie and Marvriplis2014). In order to enable the practical simulation of turbulent flows, a variety of techniques are currently in use, such as Reynolds-averaged Navier Stokes (RANS), detached eddy simulation (DES) and large eddy simulation (LES). Each technique comes with its own advantages. The user’s available computational resources are the primary consideration. The RANS technique, which models turbulence as a single-scale phenomenon, remains the most popular industrial technique due to the computational costs of scale-resolving simulations (Witherden & Jameson Reference Witherden and Jameson2017).
In recent years, a new menu item for industrial turbulence modelling is emerging. Machine learning has been used to augment RANS, DES, LES and DNS, with various objectives, such as accelerating simulation times (Kochkov et al. Reference Kochkov, Smith, Alieva, Wang, Brenner and Hoyer2021), inferring optimal coefficient fields (Singh, Duraisamy & Zhang Reference Singh, Duraisamy and Zhang2017), model calibration (Matai & Durbin Reference Matai and Durbin2019) and turbulence model augmentation (Duraisamy, Iaccarino & Xiao Reference Duraisamy, Iaccarino and Xiao2019; Brunton, Noack & Koumoutsakos Reference Brunton, Noack and Koumoutsakos2020). For LES, emerging research on training in situ and within a differentiable solver offers the prospect of a generalisable subgrid model (List, Chen & Thuerey Reference List, Chen and Thuerey2022; Sirignano & MacArt Reference Sirignano and MacArt2023). It is clear that for LES, allowing the model to interact with a solver for an unsteady flow vastly improves the generalisability of the learned closure relationship (List et al. Reference List, Chen and Thuerey2022). Within the context of steady-state RANS simulations, a promising new menu item is the ability to train a specialised turbulence model with a given industrial dataset. Significant attention has been given to the development of machine learning-augmented closure models. Specifically, flow-specific sensitisation of the stable but often inaccurate linear eddy viscosity relationship via machine learning is an area of major interest. In their seminal work, Ling, Kurzawski & Templeton (Reference Ling, Kurzawski and Templeton2016) proposed a neural network architecture based on a tensor basis expansion of the anisotropy tensor, referred to as a tensor basis neural network (TBNN). This architecture was extended to random forests by Kaandorp (Reference Kaandorp2018) and Kaandorp & Dwight (Reference Kaandorp and Dwight2020). The TBNN architecture has been used in several studies, such as by Song et al. (Reference Song, Zhang, Wang, Ye and Huang2019) and Zhang et al. (Reference Zhang, Song, Ye, Wang, Huang, An and Chen2019). Further modifications to the TBNN framework within the context of simple channel flows have been proposed by Cai et al. (Reference Cai, Angeli, Martinez, Damblin and Lucor2022, Reference Cai, Angeli, Martinez, Damblin and Lucor2024). Specifically, Cai et al. studied issues related to non-unique mappings between the closure term and input features for plane channel flow, an issue reported by Liu et al. (Reference Liu, Fang, Rolfo, Moulinec and Emerson2021). This issue primarily occurs when a small input feature set is used, such as the 5 invariants (several of which are zero for two-dimensional flows) used in Ling et al.’s original TBNN (Ling et al. Reference Ling, Kurzawski and Templeton2016). Several strategies have been proposed to address the issue of a non-unique mapping, including incorporation of additional input features by Wu, Xiao & Paterson (Reference Wu, Xiao and Paterson2018), and ensembling through a divide and conquer approach by Man et al. (Reference Man, Jadidi, Keshmiri, Yin and Mahmoudi2023). In the present investigation, we address the issue related to non-uniqueness of the mapping via use of a rich input feature set. In an effort to make these mappings more transparent, Mandler & Weigand (Reference Mandler and Weigand2023) analysed predictions made via an anisotropy mapping using input feature importance metrics such as Shapley additive explanation values. Interpretability analysis sheds light on which RANS features contain more information about different flow physics, which helps guide future input feature selection (Mandler & Weigand Reference Mandler and Weigand2023). The TBNN-type models are not the only architecture in use – others include the eigenvalue reconstruction technique proposed by Wu et al. (Reference Wu, Xiao and Paterson2018, Reference Wu, Xiao, Sun and Wang2019a ), and the Reynolds force vector approach proposed by Cruz et al. (Reference Cruz, Thompson, Sampaio and Bacchi2019), and further investigated by Brener et al. (Reference Brener, Cruz, Macedo and Thompson2022) and Amarloo, Forooghi & Abkar (Reference Amarloo, Forooghi and Abkar2022).
Here, we consider the specific problem of training data-driven anisotropy mappings between RANS and a higher fidelity closure term from LES or DNS. Several open questions remain in the area of machine learning anisotropy mappings for RANS, with perhaps the most popular question being whether a ‘universal turbulence model’ could be produced via machine learning (Duraisamy Reference Duraisamy2021; Spalart Reference Spalart2023). However, when it comes to generalisability of these mappings, the no-free-lunch theorem is at play as demonstrated in McConkey et al. (Reference McConkey, Yee and Lien2022b ). Accurate sensitisation of the anisotropy mapping for a given flow comes at the cost of generalisation to completely new flows. Nevertheless, numerous studies show that the sensitised mapping generalises well within the same flow type (Wu et al. Reference Wu, Xiao and Paterson2018; Kaandorp & Dwight Reference Kaandorp and Dwight2020; McConkey et al. Reference McConkey, Yee and Lien2022b ; Man et al. Reference Man, Jadidi, Keshmiri, Yin and Mahmoudi2023). While this lack of new flow generalisability means that a machine learning-augmented turbulence model is off the menu for some applications, it remains on the menu for many industrial applications. For example, an industrial user with LES data can leverage these techniques to develop an augmented RANS turbulence model sensitised to a flow of interest. Our opinion is that this lack of generalisability is due to a lack of sufficient data. Despite numerous datasets for this purpose being available, we believe the entire space of possible mappings between RANS input features and higher fidelity closure terms is still sparsely covered by available data. For the foreseeable future, these mappings will therefore be limited to flow-specific sensitisation.
While the generalisability question is perhaps the most popular one, several other key issues remain in training anisotropy mappings for RANS. How can predicted quantities be injected in a stable and well-conditioned manner? How can eddy viscosity-based approaches be united with TBNN-type approaches? How can we incorporate alternatives to the traditional fully connected layers in a TBNN? In this investigation, we address several of these remaining questions. We formulate an injection framework which unites TBNN-type model architectures with the more stable optimal eddy viscosity-based techniques. This unification enables stable use of the equivariance-enforcing TBNN within the momentum equation, without the use of stabilising blending factors (Kaandorp & Dwight Reference Kaandorp and Dwight2020). The proposed framework also has the advantage of producing a well-conditioned solution without the use of an optimal eddy viscosity, an often-unstable quantity that is difficult to predict via a machine learning model. We also target the problem of producing realisable predictions via a TBNN-type architecture via a physics-based loss function penalty (viz., incorporation of a learning bias in the framework). To further improve the flexibility and representational capacity of TBNN-type models, we investigate the inclusion of a Kolmogorov–Arnold network (KAN) (Liu et al. Reference Liu, Wang, Vaidya, Ruehle, Halverson, Soljačić and Hou2024) into the framework to replace the multi-layer perception in the TBNN. We also further investigate the invariant input feature sets commonly used for TBNN architectures, and provide new insights as to which input features are appropriate for use in flows with certain zero gradient directions. We demonstrate good generalisation performance of the ‘realisability-informed’ TBNN. We also demonstrate that the realisability-informed loss function greatly reduces non-realisable predictions when generalising.
The present work unites TBNN-type frameworks (for example Ling et al. Reference Ling, Kurzawski and Templeton2016; Kaandorp Reference Kaandorp2018; Kaandorp & Dwight Reference Kaandorp and Dwight2020; and Man et al. Reference Man, Jadidi, Keshmiri, Yin and Mahmoudi2023) with optimal eddy viscosity frameworks (e.g. Wu et al. Reference Wu, Xiao and Paterson2018; Brener et al. Reference Brener, Cruz, Thompson and Anjos2021; and McConkey et al. Reference McConkey, Yee and Lien2022a ). The advantage here is maintaining a stable injection environment (Wu et al. Reference Wu, Sun, Laizet and Xiao2019b ; Brener et al. Reference Brener, Cruz, Thompson and Anjos2021), while also retaining the simplicity, elegance and implicit equivariance of the TBNN architecture. Additionally, the present work is the first to implement a way to inform the TBNN of physical realisability during the training process. Whereas most existing techniques to enforce realisability of the neural network involve an ad-hoc post-processing step, our technique leverages physical realisability as an additional training target, thereby embedding an additional physics-based (learning) bias into the model. This idea extends the learning bias proposed by Riccius, Agrawal & Koutsourelakis (Reference Riccius, Agrawal and Koutsourelakis2023). Lastly, despite widespread use of minimal integrity basis input features for two-dimensional flows, and flows through a square duct, the present investigation is the first to systematically examine these input features for flow through a square duct. This examination leads to several unsuitable input features being identified, and a codebase for investigating other flows of interest.
This manuscript is organised as follows. Section 1 describes the novel techniques in detail, including the injection framework ((1.1)–(1.2)), realisability-informed loss function (1.3) and improved TBNN architecture (1.4). Details on the datasets, input features, hyperparameters, implementation and code availability are given in § 1.5. Two primary results are presented in § 2: generalisation tests of the realisability-informed TBNN (2.1), and an examination of how realisability-informed training produces more realisable predictions when generalising (2.2). Conclusions and future work are discussed in § 3.
1. Methodology
1.1. Injecting Reynolds stress tensor decompositions used in data-driven closure modelling frameworks
The steady-state, RANS momentum equations for an incompressible, Newtonian fluid are given by (Reynolds Reference Reynolds1895)
 \begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial P}{\partial x_j} + \nu \frac {\partial ^2 U_{\!j}}{\partial x_i \partial x_i} -\frac {\partial \tau _{\textit{ij}}}{\partial x_i} , \end{equation}
\begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial P}{\partial x_j} + \nu \frac {\partial ^2 U_{\!j}}{\partial x_i \partial x_i} -\frac {\partial \tau _{\textit{ij}}}{\partial x_i} , \end{equation}
where
 $U_{\!j}$
is the mean velocity,
$U_{\!j}$
is the mean velocity,
 $P$
is the mean pressure,
$P$
is the mean pressure,
 $\rho$
is the fluid density,
$\rho$
is the fluid density,
 $\nu$
is the kinematic viscosity and
$\nu$
is the kinematic viscosity and
 $\tau _{\textit{ij}}$
is the Reynolds stress tensor.
$\tau _{\textit{ij}}$
is the Reynolds stress tensor.
The continuity equation also applies to this flow
 \begin{equation} \frac {\partial U_i}{\partial x_i} = 0 . \end{equation}
\begin{equation} \frac {\partial U_i}{\partial x_i} = 0 . \end{equation}
Together, (1.1) and (1.2) are unclosed. In the most general case, there are four equations (continuity + 3 momentum), and 10 unknowns:
 $P$
, 3 components of
$P$
, 3 components of
 $U_i$
and 6 components of
$U_i$
and 6 components of
 $\tau _{\textit{ij}}$
. The goal of turbulence closure modelling is to express
$\tau _{\textit{ij}}$
. The goal of turbulence closure modelling is to express
 $\tau _{\textit{ij}}$
in terms of
$\tau _{\textit{ij}}$
in terms of
 $P$
and
$P$
and
 $U_i$
.
$U_i$
.
The Reynolds stress tensor can be decomposed into isotropic (hydrostatic) and anisotropic (deviatoric) components
 \begin{equation} \tau _{\textit{ij}} = \frac {2}{3}k\delta _{\textit{ij}} + a_{\textit{ij}} , \end{equation}
\begin{equation} \tau _{\textit{ij}} = \frac {2}{3}k\delta _{\textit{ij}} + a_{\textit{ij}} , \end{equation}
where
 $k = ({1}/{2})\tau _{kk}$
is half the trace of the Reynolds stress tensor, and
$k = ({1}/{2})\tau _{kk}$
is half the trace of the Reynolds stress tensor, and
 $a_{\textit{ij}}$
is the anisotropy tensor. The isotropic component (
$a_{\textit{ij}}$
is the anisotropy tensor. The isotropic component (
 $({2}/{3})k\delta _{\textit{ij}}$
) in (1.3) can be absorbed into the pressure gradient term in (1.1) to form a modified pressure
$({2}/{3})k\delta _{\textit{ij}}$
) in (1.3) can be absorbed into the pressure gradient term in (1.1) to form a modified pressure
 \begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \nu \frac {\partial ^2 U_{\!j}}{\partial x_i \partial x_i} -\frac {\partial a_{\textit{ij}}}{\partial x_i} . \end{equation}
\begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \nu \frac {\partial ^2 U_{\!j}}{\partial x_i \partial x_i} -\frac {\partial a_{\textit{ij}}}{\partial x_i} . \end{equation}
Equation (1.4) is the form of the RANS momentum equation commonly used in RANS turbulence closure modelling. Several data-driven closure modelling frameworks are based on modelling the Reynolds stress tensor itself, or it’s divergence (as in Brener et al. (Reference Brener, Cruz, Macedo and Thompson2022)), which imply the use of (1.1). In our work, we model the Reynolds stress anisotropy tensor
 $a_{\textit{ij}}$
, implying the use of (1.4). In either case, the term ‘injection’ refers to using a model prediction as the closure term in the momentum equation and numerically solving the momentum equation with this predicted closure term.
$a_{\textit{ij}}$
, implying the use of (1.4). In either case, the term ‘injection’ refers to using a model prediction as the closure term in the momentum equation and numerically solving the momentum equation with this predicted closure term.
In an eddy viscosity hypothesis, the anisotropy tensor
 $a_{\textit{ij}}$
is postulated to be a function of the mean strain rate
$a_{\textit{ij}}$
is postulated to be a function of the mean strain rate
 $S_{\textit{ij}}$
and rotation rate
$S_{\textit{ij}}$
and rotation rate
 $R_{\textit{ij}}$
tensors
$R_{\textit{ij}}$
tensors
 \begin{align} a_{\textit{ij}} &= a_{\textit{ij}}(S_{\textit{ij}}, R_{\textit{ij}}) , \end{align}
\begin{align} a_{\textit{ij}} &= a_{\textit{ij}}(S_{\textit{ij}}, R_{\textit{ij}}) , \end{align}
 \begin{align} S_{\textit{ij}} &= \frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} + \frac {\partial U_{\!j}}{\partial x_i}\right )\! , \end{align}
\begin{align} S_{\textit{ij}} &= \frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} + \frac {\partial U_{\!j}}{\partial x_i}\right )\! , \end{align}
 \begin{align} R_{\textit{ij}} &= \frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} - \frac {\partial U_{\!j}}{\partial x_i}\right)\!. \end{align}
\begin{align} R_{\textit{ij}} &= \frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} - \frac {\partial U_{\!j}}{\partial x_i}\right)\!. \end{align}
The eddy viscosity hypothesis implies the following important constraints:
-
(i) The anisotropy tensor can be predicted locally and instantaneously. In (1.5), there is no temporal dependence.
-
(ii) The anisotropic turbulent stresses are caused entirely by mean velocity gradients.
There are many examples of turbulent flows where these assumptions are violated (Pope Reference Pope2000). For example, history effects occur in boundary layers (Bobke et al. Reference Bobke, Vinuesa, Örlü and Schlatter2017). Nevertheless these approximations remain widely used in eddy viscosity modelling. The most common eddy viscosity hypothesis is the linear eddy viscosity hypothesis
 \begin{equation} a_{\textit{ij}} = - 2 \nu _t S_{\textit{ij}} , \end{equation}
\begin{equation} a_{\textit{ij}} = - 2 \nu _t S_{\textit{ij}} , \end{equation}
where
 $\nu _t$
is the eddy viscosity, a scalar. This linear hypothesis draws direct analogy from the stress–strain rate relation for a Newtonian fluid. Along with the important constraints implied by invoking an eddy viscosity hypothesis, the linear eddy viscosity hypothesis implies the following:
$\nu _t$
is the eddy viscosity, a scalar. This linear hypothesis draws direct analogy from the stress–strain rate relation for a Newtonian fluid. Along with the important constraints implied by invoking an eddy viscosity hypothesis, the linear eddy viscosity hypothesis implies the following:
-
(i) The anisotropy tensor is aligned with the mean strain rate tensor.
-
(ii) The mapping between mean strain rate and anisotropic stress is isotropic, in that it can be represented using a single scalar (
 $\nu _t$
).
$\nu _t$
).

More general nonlinear eddy viscosity hypotheses have been used in several models. The primary advantage of these models is that they permit a misalignment of the principal axes of
 $a_{\textit{ij}}$
and
$a_{\textit{ij}}$
and
 $S_{\textit{ij}}$
, which occurs for even simple flows. Applying Cayley–Hamilton theorem (Hamilton Reference Hamilton1853; Cayley Reference Cayley1858) to (1.5), Pope (Reference Pope1975) derived the most general expression for a nonlinear eddy viscosity model
$S_{\textit{ij}}$
, which occurs for even simple flows. Applying Cayley–Hamilton theorem (Hamilton Reference Hamilton1853; Cayley Reference Cayley1858) to (1.5), Pope (Reference Pope1975) derived the most general expression for a nonlinear eddy viscosity model
 \begin{equation} a_{\textit{ij}} = 2k \sum _{n=1}^{10} g_n \hat {T}^{(n)}_{\textit{ij}} , \end{equation}
\begin{equation} a_{\textit{ij}} = 2k \sum _{n=1}^{10} g_n \hat {T}^{(n)}_{\textit{ij}} , \end{equation}
where
 $n=1,2,\ldots 10$
indexes the scalar coefficients
$n=1,2,\ldots 10$
indexes the scalar coefficients
 $g_n$
, and the following basis tensors:
$g_n$
, and the following basis tensors:
 \begin{align} & \hat {T}^{(1)}_{\textit{ij}} =\hat {S}_{\textit{ij}}, && \!\! \hat {T}^{(6)}_{\textit{ij}}= \hat {R}_{ik} \hat {R}_{kl} \hat {S}_{lj}+ \hat {S}_{ik} \hat {R}_{kl} \hat {R}_{lj} - \tfrac {2}{3} \hat {S}_{kl}\hat {R}_{lm}\hat {R}_{mk} \delta _{\textit{ij}} ,\nonumber \\ & \hat {T}^{(2)}_{\textit{ij}} =\hat {S}_{ik} \hat {R}_{kj} - \hat {R}_{ik}\hat {S}_{kj}, && \!\! \hat {T}^{(7)}_{\textit{ij}} = \hat {R}_{ik} \hat {S}_{kl} \hat {R}_{lm}\hat {R}_{mj} - \hat {R}_{ik}\hat {R}_{kl} \hat {S}_{lm} \hat {R}_{mj},\nonumber \\ & \hat {T}^{(3)}_{\textit{ij}} =\hat {S}_{ik}\hat {S}_{kj} - \tfrac {1}{3}\hat {S}_{kl}\hat {S}_{lk} \delta _{\textit{ij}}, && \!\! \hat {T}^{(8)}_{\textit{ij}} = \hat {S}_{ik}\hat {R}_{kl}\hat {S}_{lm}\hat {S}_{mj} - \hat {S}_{ik}\hat {S}_{kl} \hat {R}_{lm} \hat {S}_{mj}, \nonumber \\ & \hat {T}^{(4)}_{\textit{ij}} \!=\! \hat {R}_{ik}\hat {R}_{kj} \!-\! \tfrac {1}{3}\hat {R}_{kl}\hat {R}_{lk}\delta _{\textit{ij}}, && \!\! \hat {T}^{(9)}_{\textit{ij}} \!=\! \hat {R}_{ik} \hat {R}_{kl}\hat {S}_{lm}\hat {S}_{mj} \!+\! \hat {S}_{ik} \hat {S}_{kl}\hat {R}_{lm}\hat {R}_{mj} \!-\! \tfrac {2}{3} \hat {S}_{kl}\hat {S}_{lm} \hat {R}_{mo}\hat {R}_{ok} \delta _{\textit{ij}}, \nonumber \\ & \hat {T}^{(5)}_{\textit{ij}} = \hat {R}_{ik} \hat {S}_{kl} \hat {S}_{lj} - \hat {S}_{ik} \hat {S}_{kl}\hat {R}_{lj}, && \!\! \hat {T}^{(10)}_{\textit{ij}} = \hat {R}_{ik}\hat {S}_{kl}\hat {S}_{lm} \hat {R}_{mo} \hat {R}_{oj} - \hat {R}_{ik}\hat {R}_{kl}\hat {S}_{lm} \hat {S}_{mo} \hat {R}_{oj}\ . \end{align}
\begin{align} & \hat {T}^{(1)}_{\textit{ij}} =\hat {S}_{\textit{ij}}, && \!\! \hat {T}^{(6)}_{\textit{ij}}= \hat {R}_{ik} \hat {R}_{kl} \hat {S}_{lj}+ \hat {S}_{ik} \hat {R}_{kl} \hat {R}_{lj} - \tfrac {2}{3} \hat {S}_{kl}\hat {R}_{lm}\hat {R}_{mk} \delta _{\textit{ij}} ,\nonumber \\ & \hat {T}^{(2)}_{\textit{ij}} =\hat {S}_{ik} \hat {R}_{kj} - \hat {R}_{ik}\hat {S}_{kj}, && \!\! \hat {T}^{(7)}_{\textit{ij}} = \hat {R}_{ik} \hat {S}_{kl} \hat {R}_{lm}\hat {R}_{mj} - \hat {R}_{ik}\hat {R}_{kl} \hat {S}_{lm} \hat {R}_{mj},\nonumber \\ & \hat {T}^{(3)}_{\textit{ij}} =\hat {S}_{ik}\hat {S}_{kj} - \tfrac {1}{3}\hat {S}_{kl}\hat {S}_{lk} \delta _{\textit{ij}}, && \!\! \hat {T}^{(8)}_{\textit{ij}} = \hat {S}_{ik}\hat {R}_{kl}\hat {S}_{lm}\hat {S}_{mj} - \hat {S}_{ik}\hat {S}_{kl} \hat {R}_{lm} \hat {S}_{mj}, \nonumber \\ & \hat {T}^{(4)}_{\textit{ij}} \!=\! \hat {R}_{ik}\hat {R}_{kj} \!-\! \tfrac {1}{3}\hat {R}_{kl}\hat {R}_{lk}\delta _{\textit{ij}}, && \!\! \hat {T}^{(9)}_{\textit{ij}} \!=\! \hat {R}_{ik} \hat {R}_{kl}\hat {S}_{lm}\hat {S}_{mj} \!+\! \hat {S}_{ik} \hat {S}_{kl}\hat {R}_{lm}\hat {R}_{mj} \!-\! \tfrac {2}{3} \hat {S}_{kl}\hat {S}_{lm} \hat {R}_{mo}\hat {R}_{ok} \delta _{\textit{ij}}, \nonumber \\ & \hat {T}^{(5)}_{\textit{ij}} = \hat {R}_{ik} \hat {S}_{kl} \hat {S}_{lj} - \hat {S}_{ik} \hat {S}_{kl}\hat {R}_{lj}, && \!\! \hat {T}^{(10)}_{\textit{ij}} = \hat {R}_{ik}\hat {S}_{kl}\hat {S}_{lm} \hat {R}_{mo} \hat {R}_{oj} - \hat {R}_{ik}\hat {R}_{kl}\hat {S}_{lm} \hat {S}_{mo} \hat {R}_{oj}\ . \end{align}
The tensors
 $\hat {S}_{\textit{ij}}$
and
$\hat {S}_{\textit{ij}}$
and
 $\hat {R}_{\textit{ij}}$
above are the non-dimensionalised strain rate and rotation rate tensors. In Pope’s original work, these tensors are given by
$\hat {R}_{\textit{ij}}$
above are the non-dimensionalised strain rate and rotation rate tensors. In Pope’s original work, these tensors are given by
 \begin{align} \hat {S}_{\textit{ij}} &= \frac {k}{\varepsilon } S_{\textit{ij}} , \end{align}
\begin{align} \hat {S}_{\textit{ij}} &= \frac {k}{\varepsilon } S_{\textit{ij}} , \end{align}
 \begin{align} \hat {R}_{\textit{ij}} &= \frac {k}{\varepsilon } R_{\textit{ij}}. \end{align}
\begin{align} \hat {R}_{\textit{ij}} &= \frac {k}{\varepsilon } R_{\textit{ij}}. \end{align}
However, other normalisation constants are possible, and in several nonlinear eddy viscosity models, different basis tensors use different normalisation constants. To our knowledge, varying the basis tensor normalisation has not been explored in data-driven turbulence closure modelling.
With Pope’s general expression for the anisotropy tensor, (1.4) becomes
 \begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \nu \frac {\partial ^2 U_{\!j}}{\partial x_i \partial x_i} -\frac {\partial }{\partial x_i}\left (2k \sum _{n=1}^{10} g_n \hat {T}^{(n)}_{\textit{ij}}\right )\! . \end{equation}
\begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \nu \frac {\partial ^2 U_{\!j}}{\partial x_i \partial x_i} -\frac {\partial }{\partial x_i}\left (2k \sum _{n=1}^{10} g_n \hat {T}^{(n)}_{\textit{ij}}\right )\! . \end{equation}
This is the form of the momentum equation used in several studies which aim to augment the closure relationship via machine learning. For example, in Ling et al.’s TBNN investigation (Ling et al. Reference Ling, Kurzawski and Templeton2016), (1.13) was used. Kaandorp (Reference Kaandorp2018) and Kaandorp & Dwight (Reference Kaandorp and Dwight2020) also used this form of the momentum equation. The TBNN-based approaches are advantageous for several reasons. The TBNN architecture is motivated by a tensor algebra-based argument that if the anisotropy tensor is to be expanded in terms of the mean strain and rotation rate tensors (a dominant approach in eddy viscosity modelling), the TBNN is the most general form of this expansion (Pope Reference Pope1975). Additionally, other techniques to incorporate equivariance are cumbersome, requiring learning and predicting in an invariant eigenframe of some tensorial quantity (Wu et al. Reference Wu, Xiao and Paterson2018; Brener et al. Reference Brener, Cruz, Macedo and Thompson2022). The TBNN-based architectures do not require computing eigenvalues of the strain rate tensor at every evaluation data point. Lastly, this closure term is highly expressive, in that ten different combinations of
 $S_{\textit{ij}}$
and
$S_{\textit{ij}}$
and
 $R_{\textit{ij}}$
can be used to represent the anisotropy tensor. However, a major disadvantage with numerically solving (1.13) is that the closure term is entirely explicit, greatly reducing numerical stability and conditioning (Brener et al. Reference Brener, Cruz, Thompson and Anjos2021). For this reason, Kaandorp & Dwight (Reference Kaandorp and Dwight2020) needed to implement a blending function, which blends the fully explicit closure term in (1.13) with the more stable implicit closure term treatment made possible with a linear eddy viscosity hypothesis. Here, implicit treatment refers to the way the velocity discretisation matrix is constructed in the numerical solver. When a term is treated implicitly, it contributes to the
$R_{\textit{ij}}$
can be used to represent the anisotropy tensor. However, a major disadvantage with numerically solving (1.13) is that the closure term is entirely explicit, greatly reducing numerical stability and conditioning (Brener et al. Reference Brener, Cruz, Thompson and Anjos2021). For this reason, Kaandorp & Dwight (Reference Kaandorp and Dwight2020) needed to implement a blending function, which blends the fully explicit closure term in (1.13) with the more stable implicit closure term treatment made possible with a linear eddy viscosity hypothesis. Here, implicit treatment refers to the way the velocity discretisation matrix is constructed in the numerical solver. When a term is treated implicitly, it contributes to the
 $U_i$
coefficient matrix. In contrast, explicit treatment refers to treating a term as a fixed source term in the discretised equation. Assuming the closure term takes the form
$U_i$
coefficient matrix. In contrast, explicit treatment refers to treating a term as a fixed source term in the discretised equation. Assuming the closure term takes the form
 $a_{\textit{ij}} = -2 \nu _t S_{\textit{ij}}$
, (1.4) can be written as
$a_{\textit{ij}} = -2 \nu _t S_{\textit{ij}}$
, (1.4) can be written as
 \begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \frac {\partial }{\partial x_i} \left [(\nu + \nu _t) \frac {\partial U_{\!j}}{\partial x_i}\right ]\! . \end{equation}
\begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \frac {\partial }{\partial x_i} \left [(\nu + \nu _t) \frac {\partial U_{\!j}}{\partial x_i}\right ]\! . \end{equation}
Equation (1.14) has the major advantage of increasing diagonal dominance of the
 $U_{\!j}$
coefficient matrix obtained from discretisation of this equation, via the eddy viscosity. However, this closure framework only permits the inaccurate linear eddy viscosity closure approximation.
$U_{\!j}$
coefficient matrix obtained from discretisation of this equation, via the eddy viscosity. However, this closure framework only permits the inaccurate linear eddy viscosity closure approximation.
In the present work, we propose the following hybrid treatment of the closure term:
 \begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \frac {\partial }{\partial x_i} \left [(\nu + \nu _t) \frac {\partial U_{\!j}}{\partial x_i}\right ] -\frac {\partial }{\partial x_i}\left (2k \sum _{n=2}^{10} g_n \hat {T}^{(n)}_{\textit{ij}}\right )\! . \end{equation}
\begin{equation} U_i \frac {\partial U_{\!j}}{\partial x_i} = -\frac {1}{\rho } \frac {\partial }{\partial x_j} \left (P+\frac {2}{3}\rho k\right ) + \frac {\partial }{\partial x_i} \left [(\nu + \nu _t) \frac {\partial U_{\!j}}{\partial x_i}\right ] -\frac {\partial }{\partial x_i}\left (2k \sum _{n=2}^{10} g_n \hat {T}^{(n)}_{\textit{ij}}\right )\! . \end{equation}
In (1.15), the
 $n=1$
(linear) term has been separated and receives implicit treatment, while the remaining
$n=1$
(linear) term has been separated and receives implicit treatment, while the remaining
 $n = 2,3,\ldots 10$
terms grant an opportunity for a machine learning model to provide rich representation of the nonlinear part of
$n = 2,3,\ldots 10$
terms grant an opportunity for a machine learning model to provide rich representation of the nonlinear part of
 $a_{\textit{ij}}$
. As we will discuss, the separation of the linear term requires special treatment during training and closure term injection.
$a_{\textit{ij}}$
. As we will discuss, the separation of the linear term requires special treatment during training and closure term injection.
1.2. Conditioning analysis
Various decompositions of the Reynolds stress tensor were investigated by Brener et al.’s conditioning analysis (Brener et al. Reference Brener, Cruz, Thompson and Anjos2021). Conditioning analysis for data-driven turbulence closure frameworks is important, since ill-conditioned momentum equations have the potential to amplify errors in the predicted closure term. Brener et al. (Reference Brener, Cruz, Thompson and Anjos2021) concluded that an optimal eddy viscosity approach is necessary to achieve a well-conditioned solution, since it incorporates information about the DNS mean velocity field. In the present work, we demonstrate that the following closure decomposition:
 \begin{equation} a_{\textit{ij}} = -2\nu ^{{R}}_{t} S^{\theta}_{\textit{ij}} + a^{\perp}_{\textit{ij}} \end{equation}
\begin{equation} a_{\textit{ij}} = -2\nu ^{{R}}_{t} S^{\theta}_{\textit{ij}} + a^{\perp}_{\textit{ij}} \end{equation}
also achieves a well-conditioned solution. We follow the nomenclature of Duraisamy et al. (Reference Duraisamy, Iaccarino and Xiao2019) in that the
 $\theta$
superscript indicates a quantity that comes from a high-fidelity source such as DNS. The
$\theta$
superscript indicates a quantity that comes from a high-fidelity source such as DNS. The
 ${{R}}$
superscript indicates a quantity taken from the corresponding baseline RANS simulation.
${{R}}$
superscript indicates a quantity taken from the corresponding baseline RANS simulation.
The decomposition in (1.16) permits an augmented turbulence closure framework that treats the machine learning correction only in an explicit term in the momentum equation. Separating the machine learning model prediction has several advantages. It allows the model correction to be easily ‘turned off’ in unstable situations. It also is more interpretable – rather than correcting both the eddy viscosity and also injecting an explicit correction term, the correction is contained entirely within an explicit term in the momentum equation. Lastly, it avoids the necessity for an optimal eddy viscosity to be computed from high-fidelity data. Although there are methods to increase the practicality of computing the optimal eddy viscosity (McConkey et al. Reference McConkey, Yee and Lien2022a ), this quantity is often unstable and difficult to predict via a machine learning model.

Figure 1. Conditioning test comparing the errors in
 $U_1$
after injecting: (a) the DNS anisotropy tensor fully explicitly, (b) the optimal eddy viscosity (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
$U_1$
after injecting: (a) the DNS anisotropy tensor fully explicitly, (b) the optimal eddy viscosity (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
 $S^\theta _{\textit{ij}}$
(explicitly), (c) the eddy viscosity estimated by the
$S^\theta _{\textit{ij}}$
(explicitly), (c) the eddy viscosity estimated by the
 $k$
-
$k$
-
 $\omega$
shear stress transport (SST) model (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
$\omega$
shear stress transport (SST) model (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
 $S^\theta _{\textit{ij}}$
(explicitly) and (d) the eddy viscosity estimated by the
$S^\theta _{\textit{ij}}$
(explicitly) and (d) the eddy viscosity estimated by the
 $k$
-
$k$
-
 $\omega$
SST model (implicitly), and the remaining nonlinear part of the anisotropy tensor calculated using
$\omega$
SST model (implicitly), and the remaining nonlinear part of the anisotropy tensor calculated using
 $S^{{R}}_{\textit{ij}}$
(explicitly),
$S^{{R}}_{\textit{ij}}$
(explicitly),
 $k$
is the turbulent kinetic energy (TKE),
$k$
is the turbulent kinetic energy (TKE),
 $\omega$
is the TKE specific dissipation rate and RSME is the Root mean squared error.
$\omega$
is the TKE specific dissipation rate and RSME is the Root mean squared error.

Figure 2. Conditioning test comparing the errors in
 $U_2$
after injecting: (a) the DNS anisotropy tensor fully explicitly, (b) the optimal eddy viscosity (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
$U_2$
after injecting: (a) the DNS anisotropy tensor fully explicitly, (b) the optimal eddy viscosity (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
 $S^\theta _{\textit{ij}}$
(explicitly), (c) the eddy viscosity estimated by the
$S^\theta _{\textit{ij}}$
(explicitly), (c) the eddy viscosity estimated by the
 $k$
-
$k$
-
 $\omega$
SST model (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
$\omega$
SST model (implicitly) and the remaining nonlinear part of the anisotropy tensor calculated using
 $S^\theta _{\textit{ij}}$
(explicitly) and (d) the eddy viscosity estimated by the
$S^\theta _{\textit{ij}}$
(explicitly) and (d) the eddy viscosity estimated by the
 $k$
-
$k$
-
 $\omega$
SST model (implicitly), and the remaining nonlinear part of the anisotropy tensor calculated using
$\omega$
SST model (implicitly), and the remaining nonlinear part of the anisotropy tensor calculated using
 $S^{{R}}_{\textit{ij}}$
(explicitly).
$S^{{R}}_{\textit{ij}}$
(explicitly).
Figures 1 and 2 demonstrate a conditioning test similar to the tests conducted by Brener et al. (Reference Brener, Cruz, Thompson and Anjos2021). Several different decompositions of the DNS Reynolds stress tensor are injected into a RANS simulation, to identify which decompositions permit a well-conditioned solution. Comparing panels (b) and (c) in both figures 1 and 2, we can see that the proposed decomposition of the Reynolds stress tensor (1.16) achieves an equally well-conditioned solution as the optimal eddy viscosity framework. To our knowledge, this is the first result in the literature showing that a well-conditioned solution can be achieved without the use of an optimal eddy viscosity to incorporate information about the DNS velocity field (Brener et al. Reference Brener, Cruz, Thompson and Anjos2021). We further confirm the findings of Brener et al. (Reference Brener, Cruz, Thompson and Anjos2021) with respect to the requirement that the closure decomposition includes information about the DNS mean velocity field in order to achieve a well-conditioned solution. We confirm the notion from Wu et al. (Reference Wu, Xiao, Sun and Wang2019a
) that implicit treatment helps address the ill-conditioning issue, but using the DNS strain rate tensor
 $S^\theta _{\textit{ij}}$
to calculate the explicitly injected
$S^\theta _{\textit{ij}}$
to calculate the explicitly injected
 $a^{\perp}_{\textit{ij}}$
.
$a^{\perp}_{\textit{ij}}$
.
1.3. Realisability-informed training
The Reynolds stress tensor is symmetric positive semidefinite. A set of constraints on the non-dimensional anisotropy tensor
 $b_{\textit{ij}}$
arise from this property, as determined by Banerjee et al. (Reference Banerjee, Krahl, Durst and Zenger2007). These constraints are
$b_{\textit{ij}}$
arise from this property, as determined by Banerjee et al. (Reference Banerjee, Krahl, Durst and Zenger2007). These constraints are
 \begin{align} -\frac {1}{3} \leqslant b_{\textit{ij}} &\leqslant \frac {2}{3}, \,\, i= j, \end{align}
\begin{align} -\frac {1}{3} \leqslant b_{\textit{ij}} &\leqslant \frac {2}{3}, \,\, i= j, \end{align}
 \begin{align} -\frac {1}{2} \leqslant b_{\textit{ij}} &\leqslant \frac {1}{2}, \,\, i\neq j, \end{align}
\begin{align} -\frac {1}{2} \leqslant b_{\textit{ij}} &\leqslant \frac {1}{2}, \,\, i\neq j, \end{align}
 \begin{align} \lambda _1 &\geqslant \frac {3|\lambda _2| - \lambda _2}{2}, \end{align}
\begin{align} \lambda _1 &\geqslant \frac {3|\lambda _2| - \lambda _2}{2}, \end{align}
 \begin{align} \lambda _1 &\leqslant \frac {1}{3}- \lambda _2, \\[6pt] \nonumber \end{align}
\begin{align} \lambda _1 &\leqslant \frac {1}{3}- \lambda _2, \\[6pt] \nonumber \end{align}
where the non-dimensional anisotropy tensor
 $b_{\textit{ij}}$
is calculated by
$b_{\textit{ij}}$
is calculated by
 \begin{equation} b_{\textit{ij}} = \frac {a_{\textit{ij}}}{2k} , \end{equation}
\begin{equation} b_{\textit{ij}} = \frac {a_{\textit{ij}}}{2k} , \end{equation}
and the eigenvalues of
 $b_{\textit{ij}}$
are given by
$b_{\textit{ij}}$
are given by
 $\lambda _1 \geqslant \lambda _2 \geqslant \lambda _3$
.
$\lambda _1 \geqslant \lambda _2 \geqslant \lambda _3$
.
A given Reynolds stress tensor is physically realisable if it satisfies these constraints. While the physical realisability of the closure term may seem an important constraint for turbulence models, many commonly used turbulence models such as the
 $k$
-
$k$
-
 $\varepsilon$
model,
$\varepsilon$
model,
 $\varepsilon$
is the TKE dissipation rate (Launder & Spalding Reference Launder and Spalding1974),
$\varepsilon$
is the TKE dissipation rate (Launder & Spalding Reference Launder and Spalding1974),
 $k$
-
$k$
-
 $\omega$
(Wilcox Reference Wilcox1988) and
$\omega$
(Wilcox Reference Wilcox1988) and
 $k$
-
$k$
-
 $\omega$
SST model (Menter Reference Menter1994; Menter, Kuntz & Langtry Reference Menter, Kuntz and Langtry2003) do not guarantee physical realisability.
$\omega$
SST model (Menter Reference Menter1994; Menter, Kuntz & Langtry Reference Menter, Kuntz and Langtry2003) do not guarantee physical realisability.
Based on the widespread acceptance and popularity of non-realisable turbulence models, it is fair to say that realisability is not a hard constraint on a new turbulence model. Nevertheless, the true Reynolds stress tensor is realisable, and if a machine learning model is able to learn to predict realisable closure terms, it may be more physically accurate. Unfortunately, Pope’s tensor basis expansion for the anisotropy tensor (and machine learning architectures based on this expansion) do not provide a means to achieve realisability. To enforce realisability, a variety of ad hoc strategies have been used, including in the original TBNN paper by Ling et al. (Reference Ling, Kurzawski and Templeton2016). Most of these strategies involve postprocessing predictions by the TBNN, such as shrinking the predicted anisotropy tensor in certain directions until it is physically realisable (Jiang et al. Reference Jiang, Vinuesa, Chen, Mi, Laima and Li2021).
In the present work, we propose including a penalty for violating realisability constraints in the loss function. In a similar spirit of physics-informed neural networks (PINNs) (Raissi, Perdikaris & Karniadakis Reference Raissi, Perdikaris and Karniadakis2019), we term the use of this loss function ‘realisability-informed training’. Whereas PINNs encourage the model to learn physics by penalising violations of conservation laws, realisability-informed TBNNs learn to predict physically realisable anisotropy tensors.
The realisability penalty
 $\mathcal{R}(b_{\textit{ij}})$
is given as follows:
$\mathcal{R}(b_{\textit{ij}})$
is given as follows:
 \begin{align} \mathcal{R}(\tilde b_{\textit{ij}}) &= \frac {1}{6}\left \lbrace \sum _{i=j} \left ( {\textrm{max}}\left [\tilde b_{\textit{ij}}-\frac {2}{3}, - \left (\tilde b_{\textit{ij}}+\frac {1}{3}\right )\!, 0\right ] \right )^2 \right . \nonumber \\ &\quad +\, \left . \sum _{i\neq j} \left ({\textrm{max}}\left [\tilde b_{\textit{ij}}-\frac {1}{2}, - \left (\tilde b_{\textit{ij}}+\frac {1}{2}\right )\!, 0\right ]\right )^2 \right \rbrace \nonumber \\ &\quad +\, \frac {1}{2}\left \lbrace \left ({\textrm{max}}\left [\frac {3|\lambda _2| - |\lambda _2|}{2} - \lambda _1, 0 \right ]\right )^2 \right . \nonumber \\ &\quad +\, \left . \left ({\textrm{max}}\left [\lambda _1 - \left ( \frac {1}{3}-\lambda _2\right )\!,0 \right ] \right )^2 \right \rbrace \!, \end{align}
\begin{align} \mathcal{R}(\tilde b_{\textit{ij}}) &= \frac {1}{6}\left \lbrace \sum _{i=j} \left ( {\textrm{max}}\left [\tilde b_{\textit{ij}}-\frac {2}{3}, - \left (\tilde b_{\textit{ij}}+\frac {1}{3}\right )\!, 0\right ] \right )^2 \right . \nonumber \\ &\quad +\, \left . \sum _{i\neq j} \left ({\textrm{max}}\left [\tilde b_{\textit{ij}}-\frac {1}{2}, - \left (\tilde b_{\textit{ij}}+\frac {1}{2}\right )\!, 0\right ]\right )^2 \right \rbrace \nonumber \\ &\quad +\, \frac {1}{2}\left \lbrace \left ({\textrm{max}}\left [\frac {3|\lambda _2| - |\lambda _2|}{2} - \lambda _1, 0 \right ]\right )^2 \right . \nonumber \\ &\quad +\, \left . \left ({\textrm{max}}\left [\lambda _1 - \left ( \frac {1}{3}-\lambda _2\right )\!,0 \right ] \right )^2 \right \rbrace \!, \end{align}
where the
 $\sim$
above a symbol denotes a model prediction for the quantity associated with the symbol.
$\sim$
above a symbol denotes a model prediction for the quantity associated with the symbol.
Equation (1.22) can be thought of as the mean squared violation in the components of
 $\tilde b_{\textit{ij}}$
, plus the mean squared violation in the eigenvalues of
$\tilde b_{\textit{ij}}$
, plus the mean squared violation in the eigenvalues of
 $\tilde b_{\textit{ij}}$
. To help visualise this penalty function, figure 3 shows the penalties incurred by violating various realisability constraints on the anisotropy tensor.
$\tilde b_{\textit{ij}}$
. To help visualise this penalty function, figure 3 shows the penalties incurred by violating various realisability constraints on the anisotropy tensor.

Figure 3. Realisability penalty for the (a) diagonal components of
 $b_{\textit{ij}}$
, and (b) off-diagonal components of
$b_{\textit{ij}}$
, and (b) off-diagonal components of
 $b_{\textit{ij}}$
.
$b_{\textit{ij}}$
.
It should be noted that in the same way that a PINN’s prediction cannot be guaranteed to satisfy a conservation law, a realisability-informed TBNN cannot be guaranteed to predict a physically realisable anisotropy tensor. The goal is that the incorporation of a physics-based loss at training time will encode into the model a tendency to predict physically realisable anisotropy tensors. At training time, when the model predicts a
 $b_{\textit{ij}}$
component outside the realisability zone, then it is penalised in two ways: the error in this prediction will be non-zero (since all label data are realisable), and the realisability penalty will be non-zero. Therefore, the realisability penalty serves as an additional driving factor towards the realisable, true
$b_{\textit{ij}}$
component outside the realisability zone, then it is penalised in two ways: the error in this prediction will be non-zero (since all label data are realisable), and the realisability penalty will be non-zero. Therefore, the realisability penalty serves as an additional driving factor towards the realisable, true
 $b_{\textit{ij}}$
value. The merits of this approach are demonstrated in § 2.2.
$b_{\textit{ij}}$
value. The merits of this approach are demonstrated in § 2.2.
Another important metric in the loss function is the error-based penalty
 $\mathcal{E}(\tilde b_{\textit{ij}})$
. When the model predicts a certain anisotropy tensor, it is evaluated against a known high-fidelity anisotropy tensor available in the training dataset. Typically, mean-squared error loss functions are used to train machine learning-augmented closure models. However, we propose the following modifications to the loss function of a TBNN.
$\mathcal{E}(\tilde b_{\textit{ij}})$
. When the model predicts a certain anisotropy tensor, it is evaluated against a known high-fidelity anisotropy tensor available in the training dataset. Typically, mean-squared error loss functions are used to train machine learning-augmented closure models. However, we propose the following modifications to the loss function of a TBNN.
-
(i) Since
$b_{\textit{ij}}$
is a symmetric tensor, we propose to sum the squared errors as follows:(1.23)Calculating the squared error in this way avoids double penalising the off-diagonal components, a situation which arises when summing over all components of
\begin{equation} \mathcal{E}(\tilde b_{\textit{ij}}) = \frac {1}{6}\left \lbrace \sum _{\substack {\textit{ij} \in \lbrace 11, 12, 13,\\ 22,23,33\rbrace }} \big(\tilde b_{\textit{ij}} - b^\theta _{\textit{ij}}\big)^2 \right \rbrace \!. \end{equation}
$b_{\textit{ij}}$
.
-
(ii) Although the TBNN model predicts
$b_{\textit{ij}}$
, we propose to use a loss function based on the error in
$a_{\textit{ij}}$
. Near the wall,
$\hat {T}^{(n)}_{\textit{ij}}\rightarrow 0$
, but
$b_{\textit{ij}} \nrightarrow 0$
. The vanishing of
$\hat {T}^{(n)}_{\textit{ij}}$
with non-vanishing
$b_{\textit{ij}}$
causes instabilities during training, leading to
$g_n \rightarrow \infty$
here. Since
$a_{\textit{ij}}$
is the tensor injected into the momentum equation, its accurate prediction should be the focus of the training process. To dimensionalise
$b_{\textit{ij}}$
, the turbulent kinetic energy
$k$
must be used. This leads to the following error-based loss:(1.24)or stated more simply
\begin{equation} \mathcal{E}(\tilde a_{\textit{ij}}) = \frac {1}{6}\left \lbrace \sum _{\substack { \textit{ij} \in \lbrace 11, 12, 13,\\ 22,23,33\rbrace }} \big( 2k^\theta \tilde b_{\textit{ij}} - 2k^\theta b^\theta _{\textit{ij}}\big)^2 \right \rbrace = \frac {2(k^\theta )^2}{3}\left \lbrace \sum _{\substack { \textit{ij} \in \lbrace 11, 12, 13,\\ 22,23,33\rbrace }} \big(\tilde b_{\textit{ij}} - b^\theta _{\textit{ij}}\big)^2 \right \rbrace\! , \end{equation}
(1.25)The reason for the use of
\begin{equation} \mathcal{E}(\tilde a_{\textit{ij}})=(2k^\theta )^2 \mathcal{E}(\tilde b_{\textit{ij}}) . \end{equation}
$k^\theta$
in (1.24) and (1.25) is discussed in § 1.4.
















The final loss function includes an error-based metric and a realisability-violation penalty. This loss function
 $\mathcal{L}$
is given by
$\mathcal{L}$
is given by
 \begin{equation} \mathcal{L} = \frac {1}{N}\sum _{p} \frac {\big(2k^\theta _p\big)^2}{\displaystyle \sum _{k=1}^s Z_k^2 {\mathcal I}_{C_k}(p)}\big( \mathcal{E}\big(\tilde b_{ij,p}\big)+\alpha \mathcal R\big(\tilde b_{ij,p}\big)\big), \end{equation}
\begin{equation} \mathcal{L} = \frac {1}{N}\sum _{p} \frac {\big(2k^\theta _p\big)^2}{\displaystyle \sum _{k=1}^s Z_k^2 {\mathcal I}_{C_k}(p)}\big( \mathcal{E}\big(\tilde b_{ij,p}\big)+\alpha \mathcal R\big(\tilde b_{ij,p}\big)\big), \end{equation}
where
 $\alpha$
is a factor used to control the relative importance of the realisability penalty. Here,
$\alpha$
is a factor used to control the relative importance of the realisability penalty. Here,
 $N$
is the total number of points in the dataset. The points are indexed by
$N$
is the total number of points in the dataset. The points are indexed by
 $p = 1,2,\ldots ,N$
. The cases in the dataset are indexed
$p = 1,2,\ldots ,N$
. The cases in the dataset are indexed
 $k=1,2,\ldots ,s$
.
$k=1,2,\ldots ,s$
.
 ${\mathcal I}_{C_k}(p)$
is an indicator function
${\mathcal I}_{C_k}(p)$
is an indicator function
 \begin{equation} {\mathcal I}_{C_k}(p) = \begin{cases} 1,\quad {\textrm{if}} p \in C_k,\\ 0 \quad {\textrm{otherwise}}. \end{cases} \end{equation}
\begin{equation} {\mathcal I}_{C_k}(p) = \begin{cases} 1,\quad {\textrm{if}} p \in C_k,\\ 0 \quad {\textrm{otherwise}}. \end{cases} \end{equation}
For a given point
 $p$
,
$p$
,
 ${\mathcal I}_{C_k}(p)$
selects all points which come from the same case as
${\mathcal I}_{C_k}(p)$
selects all points which come from the same case as
 $p$
. The denominator for all points from the same case
$p$
. The denominator for all points from the same case
 $C_k$
is the same – normalisation is applied on a case-by-case basis. A given point is normalised by the mean-squared Frobenius norm of the anisotropy tensor over all the points from the case it comes from. The mean Frobenius norm over a case is given by
$C_k$
is the same – normalisation is applied on a case-by-case basis. A given point is normalised by the mean-squared Frobenius norm of the anisotropy tensor over all the points from the case it comes from. The mean Frobenius norm over a case is given by
 \begin{equation} Z_k = \frac {1}{|C_k|}\sum _{p \in C_k} \| a_{\textit{ij}}(p)\|_F\ ,\qquad k=1,2,\ldots ,s\ , \end{equation}
\begin{equation} Z_k = \frac {1}{|C_k|}\sum _{p \in C_k} \| a_{\textit{ij}}(p)\|_F\ ,\qquad k=1,2,\ldots ,s\ , \end{equation}
where
 $|C_k|$
is the cardinality of the case
$|C_k|$
is the cardinality of the case
 $C_k$
(viz., the number of points in the
$C_k$
(viz., the number of points in the
 $k$
th case
$k$
th case
 $C_k$
). Here,
$C_k$
). Here,
 $Z_k$
is simply the average of the Frobenius norm
$Z_k$
is simply the average of the Frobenius norm
 $\| \boldsymbol{\cdot } \|_F$
of the anisotropy tensor
$\| \boldsymbol{\cdot } \|_F$
of the anisotropy tensor
 $a_{\textit{ij}}$
for all points
$a_{\textit{ij}}$
for all points
 $p$
(viz.,
$p$
(viz.,
 $a_{\textit{ij}}(p)$
) in case
$a_{\textit{ij}}(p)$
) in case
 $C_k$
. The objective of this denominator in (1.26) is to promote a more balanced regression problem, since data points from various cases or flow types may have
$C_k$
. The objective of this denominator in (1.26) is to promote a more balanced regression problem, since data points from various cases or flow types may have
 $||a_{\textit{ij}}||$
that differ by orders of magnitude. Normalisation on a case-by-case basis is made in an effort to normalise all
$||a_{\textit{ij}}||$
that differ by orders of magnitude. Normalisation on a case-by-case basis is made in an effort to normalise all
 $a_{\textit{ij}}$
error magnitudes to a similar scale.
$a_{\textit{ij}}$
error magnitudes to a similar scale.
In this study, we use
 $\alpha =10^2$
to encode a high preference for realisable results in § 2. Lower values of
$\alpha =10^2$
to encode a high preference for realisable results in § 2. Lower values of
 $\alpha$
will reduce the penalty applied to realisability violations, which may be necessary for flows in which the anisotropy tensor is difficult to predict via a TBNN. As discussed, the multiplicative term
$\alpha$
will reduce the penalty applied to realisability violations, which may be necessary for flows in which the anisotropy tensor is difficult to predict via a TBNN. As discussed, the multiplicative term
 $(2k^\theta )^2$
is used to formulate the loss function in terms of predicting
$(2k^\theta )^2$
is used to formulate the loss function in terms of predicting
 $a_{\textit{ij}}$
rather than
$a_{\textit{ij}}$
rather than
 $b_{\textit{ij}}$
. However,
$b_{\textit{ij}}$
. However,
 $\mathcal{R}(\tilde b_{\textit{ij}})$
is also multiplied by
$\mathcal{R}(\tilde b_{\textit{ij}})$
is also multiplied by
 $(2k^\theta )^2$
to ensure that the realisability penalty and mean-squared error in
$(2k^\theta )^2$
to ensure that the realisability penalty and mean-squared error in
 $a_{\textit{ij}}$
are of similar scales.
$a_{\textit{ij}}$
are of similar scales.
1.4. Neural network architecture
Motivated by improving the training and injection stability, as well as generalisability, we propose several modifications to the original TBNN (Ling et al. Reference Ling, Kurzawski and Templeton2016).
The original TBNN is shown in figure 4. At training time, this network predicts the non-dimensional anisotropy tensor
 $b_{\textit{ij}}$
. All basis tensors used in this prediction at training time come from RANS, and during training the prediction
$b_{\textit{ij}}$
. All basis tensors used in this prediction at training time come from RANS, and during training the prediction
 $\tilde b_{\textit{ij}}$
is evaluated against a known value of
$\tilde b_{\textit{ij}}$
is evaluated against a known value of
 $b^\theta _{\textit{ij}}$
from a high-fidelity simulation. At injection time, the network is used in this same configuration to predict
$b^\theta _{\textit{ij}}$
from a high-fidelity simulation. At injection time, the network is used in this same configuration to predict
 $\tilde b_{\textit{ij}}$
. Here,
$\tilde b_{\textit{ij}}$
. Here,
 $\tilde b_{\textit{ij}}$
is injected into a coupled system of equations consisting of the continuity/momentum equations (explicit injection), as well as the turbulence transport equations. This system of equations is iterated around a fixed
$\tilde b_{\textit{ij}}$
is injected into a coupled system of equations consisting of the continuity/momentum equations (explicit injection), as well as the turbulence transport equations. This system of equations is iterated around a fixed
 $\tilde b_{\textit{ij}}$
, to obtain an updated estimate for the turbulent kinetic energy
$\tilde b_{\textit{ij}}$
, to obtain an updated estimate for the turbulent kinetic energy
 $k$
, and therefore an updated estimate for
$k$
, and therefore an updated estimate for
 $\tilde a_{\textit{ij}} = 2 k \tilde b_{\textit{ij}}$
.
$\tilde a_{\textit{ij}} = 2 k \tilde b_{\textit{ij}}$
.

Figure 4. Model architecture and training configuration for the original TBNN proposed by Ling et al. (Reference Ling, Kurzawski and Templeton2016).
The modified TBNN is shown in figure 5. This TBNN relies on the same tensor basis expansion as the original TBNN. However, the linear term has been modified in this expansion. Whereas the original TBNN uses
 \begin{equation} \hat {T}^{(1)}_{\textit{ij}} = \frac {k^{{R}}}{\varepsilon ^{{R}}}S^{{R}}_{\textit{ij}} , \end{equation}
\begin{equation} \hat {T}^{(1)}_{\textit{ij}} = \frac {k^{{R}}}{\varepsilon ^{{R}}}S^{{R}}_{\textit{ij}} , \end{equation}
our modified TBNN uses
 \begin{equation} \hat {T}^{(1)}_{\textit{ij}} = \frac {\nu _t^{{R}}}{k^\theta }S^\theta _{\textit{ij}} . \end{equation}
\begin{equation} \hat {T}^{(1)}_{\textit{ij}} = \frac {\nu _t^{{R}}}{k^\theta }S^\theta _{\textit{ij}} . \end{equation}

Figure 5. Model architecture and training configuration proposed in the present investigation. Note that during training,
 $S^\theta _{\textit{ij}}$
is used in
$S^\theta _{\textit{ij}}$
is used in
 $\hat {T}^{(1)}_{\textit{ij}}$
, whereas all other quantities come from the original RANS simulation.
$\hat {T}^{(1)}_{\textit{ij}}$
, whereas all other quantities come from the original RANS simulation.
Further, while the original TBNN calculates the linear (denoted by superscript
 ${\textrm{L}}$
) component of
${\textrm{L}}$
) component of
 $b_{\textit{ij}}$
as
$b_{\textit{ij}}$
as
 \begin{equation} b^{\textit{L}}_{\textit{ij}} = g_1 \hat {T}^{(1)}_{\textit{ij}} = g_1\frac {k}{\varepsilon }S_{\textit{ij}} , \end{equation}
\begin{equation} b^{\textit{L}}_{\textit{ij}} = g_1 \hat {T}^{(1)}_{\textit{ij}} = g_1\frac {k}{\varepsilon }S_{\textit{ij}} , \end{equation}
our modified TBNN uses
 \begin{equation} b^{\textit{L}}_{\textit{ij}} = - \hat {T}^{(1)}_{\textit{ij}} = - \frac {\nu _t}{k}S_{\textit{ij}} , \end{equation}
\begin{equation} b^{\textit{L}}_{\textit{ij}} = - \hat {T}^{(1)}_{\textit{ij}} = - \frac {\nu _t}{k}S_{\textit{ij}} , \end{equation}
where the superscript
 ${{R}}$
denotes a quantity that comes from the original RANS simulation.
${{R}}$
denotes a quantity that comes from the original RANS simulation.
These changes are motivated by the following.
-
(i) At injection time, we use implicit treatment of the linear term
$\hat {T}^{(1)}_{\textit{ij}}$
to formulate (1.15) in a stable manner. After injection,
$S_{\textit{ij}}$
will continue to evolve. In a similar spirit as optimal eddy viscosity frameworks, we therefore use
$S^\theta _{\textit{ij}}$
to compute the linear component at training time. In optimal eddy viscosity based frameworks, using
$S_{\textit{ij}} = S^\theta _{\textit{ij}}$
at training time helps drive
$U_{\!j}\rightarrow U^\theta _{\!j}$
at injection time (the cause of this behaviour is currently unknown). In Ling et al. (Reference Ling, Kurzawski and Templeton2016), all basis tensors (and therefore
$b_{\textit{ij}}$
) remain fixed after injection. We also fixed
$\nu _t$
=
$\nu ^{{R}}_t$
at injection time (viz., no further evolution of the eddy viscosity is permitted). -
(ii) At training time, we dimensionalise
$\tilde b_{\textit{ij}}$
using
$k^\theta$
:
$\tilde a_{\textit{ij}} = 2k^\theta \tilde b_{\textit{ij}}$
. At evaluation time, we do not have
$k^\theta$
. However, the need for
$k^\theta$
is avoided, since we only use the nonlinear part of
$\tilde b_{\textit{ij}}$
at test time. The reason we only need
$\tilde b^{\perp}_{\textit{ij}}$
at test time is that the training process has been designed to use the linear part of
$b_{\textit{ij}}$
estimated by the RANS turbulence model, and augment this by the TBNN’s equivariant prediction for
$\tilde b^{\perp}_{\textit{ij}}$
. -
(iii) Using
$\nu _t/k$
to normalise the basis tensors and fixing
$g_1=-1$
in (1.32) results in the RANS prediction for
$b^{\textit{L}}_{\textit{ij}}$
being implicitly used in the TBNN. Therefore, the TBNN learns to correct
$b_{\textit{ij}}$
using
$b^{\perp}_{\textit{ij}}$
in a way that allows a realisability-informed training process, and fully implicit treatment of the linear term at injection time.






















Lastly, the use of
 $k^\theta$
to dimensionalise
$k^\theta$
to dimensionalise
 $\tilde b_{\textit{ij}}$
is also enabled by our use of a separate neural network to correct
$\tilde b_{\textit{ij}}$
is also enabled by our use of a separate neural network to correct
 $k^{{R}}$
at injection time. This neural network is called the
$k^{{R}}$
at injection time. This neural network is called the
 $k$
-correcting neural network (KCNN), and is a simple fully connected feed-forward neural network that predicts a single output scalar
$k$
-correcting neural network (KCNN), and is a simple fully connected feed-forward neural network that predicts a single output scalar
 $\varDelta$
(Figure 6)
$\varDelta$
(Figure 6)
 \begin{equation} \varDelta = \log \left (\frac {k^\theta }{k^{{R}}}\right )\! , \end{equation}
\begin{equation} \varDelta = \log \left (\frac {k^\theta }{k^{{R}}}\right )\! , \end{equation}
such that at injection time, an updated estimate for
 $k$
can be obtained
$k$
can be obtained
 $\tilde k = {e}^\varDelta k^{{R}}$
, without the need to re-couple the turbulence transport equations. The KCNN shares the same input features as the TBNN.
$\tilde k = {e}^\varDelta k^{{R}}$
, without the need to re-couple the turbulence transport equations. The KCNN shares the same input features as the TBNN.

Figure 6. Test-time injection configuration proposed in the present investigation. The hatching over
 $g_1$
and
$g_1$
and
 $\hat {T}^{(1)}_{\textit{ij}}$
indicates that they are not used at injection time.
$\hat {T}^{(1)}_{\textit{ij}}$
indicates that they are not used at injection time.
Together, the KCNN and TBNN predict the anisotropy tensor in the following manner:
 \begin{equation} \tilde a_{\textit{ij}} = 2 \big(e^\varDelta k^{{R}} \big) \sum _{n=1}^{10}g_{n} \hat {T}^{(n)}_{\textit{ij}} . \end{equation}
\begin{equation} \tilde a_{\textit{ij}} = 2 \big(e^\varDelta k^{{R}} \big) \sum _{n=1}^{10}g_{n} \hat {T}^{(n)}_{\textit{ij}} . \end{equation}
With the linear component of
 $\tilde a_{\textit{ij}}$
being treated implicitly during injection, the entire closure framework is summarised as explicit injection of the following term into the momentum equation:
$\tilde a_{\textit{ij}}$
being treated implicitly during injection, the entire closure framework is summarised as explicit injection of the following term into the momentum equation:
 \begin{equation} \tilde a^{\perp}_{\textit{ij}} = 2 \big(e^\varDelta k^{{R}}\big) \sum _{n=2}^{10} g_{n} \hat {T}^{(n){{R}}}_{\textit{ij}} . \end{equation}
\begin{equation} \tilde a^{\perp}_{\textit{ij}} = 2 \big(e^\varDelta k^{{R}}\big) \sum _{n=2}^{10} g_{n} \hat {T}^{(n){{R}}}_{\textit{ij}} . \end{equation}
1.4.1. Tensor basis Kolmogorov–Arnold network (TBKAN)
The tensor basis KAN shown in figure 7 in the training configuration replaces the multi-layer perceptron in the modified TBNN with a KAN introduced by Liu et al. (Reference Liu, Wang, Vaidya, Ruehle, Halverson, Soljačić and Hou2024). The Kolmogorov–Arnold representation theorem states that any continuous multivariate function can be expressed as a composition of continuous univariate functions. KANs are based on this theorem, replacing the typical linear weight matrices in neural networks with learnable one-dimensional (1-D) functions (Liu et al. Reference Liu, Wang, Vaidya, Ruehle, Halverson, Soljačić and Hou2024). These functions are parameterised using splines, offering a flexible and computationally efficient approach to represent continuous functions. The KANs utilise B-splines, which are piecewise polynomial functions, to model local variations in data. Each spline segment corresponds to a polynomial function, and their piecewise nature allows KANs to approximate the local variations in the data during training. This adaptability enables KANs to capture intricate functional relationships more effectively, merging the advantages of B-splines with the traditional neural network framework, thereby enhancing both accuracy and interpretability.
In the TBKAN architecture, KAN replaces the hidden layers of the standard TBNN, while the anisotropy mapping portion remains unchanged. The TBKAN’s output layer is designed to predict the coefficients of the tensor basis.

Figure 7. Model architecture and training configuration for TBKAN which replaces the multi-layer perceptron in the modified TBNN (see figure 5) with a KAN.
1.5. Machine learning procedure
The KCNN, TBNN and TBKAN architectures proposed in § 1.4 were implemented in PyTorch, along with the proposed realisability-informed loss function (1.26). These models were trained using an open-source dataset for data-driven turbulence modelling (McConkey, Yee & Lien Reference McConkey, Yee and Lien2021). The objective of this study is to train and evaluate models trained on various flows, to determine whether the proposed realisability-informed loss function and architecture modifications are significantly beneficial. All code is available on Github (McConkey & Kalia Reference McConkey and Kalia2024).
1.5.1. Datasets
The training flows consist of flow over periodic hills (Xiao et al. Reference Xiao, Wu, Laizet and Duan2020), flow through a square duct (Pinelli et al. Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010) and flow over a flat plate with zero pressure gradient (Rumsey Reference Rumsey2021). These flows are selected because they contain several challenging physical phenomena for RANS, including separation, reattachment and Prandtl’s secondary flows. The flat plate case is also included, to demonstrate how machine learning can improve the anisotropy estimates within the boundary layer. For each flow type, both a hold-out validation set and a hold-out test set are selected. The validation set is used during training to help guide when to stop training in order to prevent overfitting, but the validation set loss is not back propagated through the network to update weights and biases. While we hold out an entire case for the test set (the usual procedure in data-driven turbulence modelling), we also generate the validation sets by holding out entire cases at a time. We recommend this method for generating validation sets in data-driven turbulence modelling – it is analogous to grouped cross-validation, a practice used in machine learning where several data points come from a single observation. Here, we consider each separate flow case as a single observation, each containing many data points. It is therefore prudent to ensure that two data points from the same observation are not used in both the training and test set.
Table 1 outlines the three training/validation/test splits considered. The objective in splitting the dataset this way is to determine whether a realisability-informed model can generalise to a new case for a given flow. Machine learning-based anisotropy mappings do not generalise well to entirely new flows (Duraisamy Reference Duraisamy2021; McConkey et al. Reference McConkey, Yee and Lien2022b ; Man et al. Reference Man, Jadidi, Keshmiri, Yin and Mahmoudi2023). However, they can be used to dramatically enhance the performance of a RANS simulation for a given flow type. In this same spirit, we aim to test how our modifications improve the generalisability of the learned anisotropy mapping to an unseen flow, albeit within the same class of flow.
Table 1. Datasets used for training, validation and testing. Varied parameters are defined in § 2.1.

1.5.2. Input features
The input features here are all derived from the baseline RANS
 $k$
-
$k$
-
 $\omega$
SST simulation. The input features form the vector
$\omega$
SST simulation. The input features form the vector
 $x^{{R}}_m$
. The superscript
$x^{{R}}_m$
. The superscript
 ${{R}}$
has been dropped in this section to avoid crowded notation, but it applies to all quantities discussed in § 1.5.2.
${{R}}$
has been dropped in this section to avoid crowded notation, but it applies to all quantities discussed in § 1.5.2.
The input features must be Galilean invariant in order to generate an appropriately constrained anisotropy mapping. Most data-driven anisotropy mapping investigations use a mixture of heuristic scalars and scalars systematically generated from a minimal integrity basis for a set of gradient tensors (Wu et al. Reference Wu, Xiao and Paterson2018). We emphasise that all scalars must be Galilean invariant – without this criterion, the RANS equations will lose Galilean invariance. Despite the importance of this constraint, several data-driven anisotropy mappings include scalars like the turbulence intensity, which breaks Galilean invariance.
We use a mixture of heuristic scalars and scalars systematically generated from a minimal integrity basis (Wu et al. Reference Wu, Xiao and Paterson2018). We use the following heuristic scalars:
 \begin{align} q_1 &= {\textrm{min}}\left (\frac {\sqrt {k} y_w}{50 \nu },2\right )\!, \end{align}
\begin{align} q_1 &= {\textrm{min}}\left (\frac {\sqrt {k} y_w}{50 \nu },2\right )\!, \end{align}
 \begin{align} q_2 &= \frac {k}{\varepsilon } \sqrt {\sum _{i} \sum _{\!j} |S_{\textit{ij}}|^2}, \end{align}
\begin{align} q_2 &= \frac {k}{\varepsilon } \sqrt {\sum _{i} \sum _{\!j} |S_{\textit{ij}}|^2}, \end{align}
 \begin{align} q_3 &= \frac {\sqrt {\displaystyle \sum _{i} \displaystyle \sum _{\!j} |\tau _{\textit{ij}}|^2}}{k} , \end{align}
\begin{align} q_3 &= \frac {\sqrt {\displaystyle \sum _{i} \displaystyle \sum _{\!j} |\tau _{\textit{ij}}|^2}}{k} , \end{align}
 \begin{align} q_4 &= \frac {\sqrt {k}}{0.09\omega y_w} , \end{align}
\begin{align} q_4 &= \frac {\sqrt {k}}{0.09\omega y_w} , \end{align}
 \begin{align} q_5 &= \frac {500\nu }{y_w^2 \omega } , \end{align}
\begin{align} q_5 &= \frac {500\nu }{y_w^2 \omega } , \end{align}
 \begin{align} q_6 &= {\textrm{min}}\left ({\textrm{max}}\left (q_4,q_5\right )\!,\frac {2.0k}{{\textrm{max}}\left (\dfrac {y_w^2}{\omega }\dfrac {\partial k}{\partial x_i}\dfrac {\partial \omega }{\partial x_i}\right )}\right )\! , \\[6pt] \nonumber \end{align}
\begin{align} q_6 &= {\textrm{min}}\left ({\textrm{max}}\left (q_4,q_5\right )\!,\frac {2.0k}{{\textrm{max}}\left (\dfrac {y_w^2}{\omega }\dfrac {\partial k}{\partial x_i}\dfrac {\partial \omega }{\partial x_i}\right )}\right )\! , \\[6pt] \nonumber \end{align}
with
 $\varepsilon = 0.09 \omega$
, and
$\varepsilon = 0.09 \omega$
, and
 $y_w$
is the distance to the nearest wall.
$y_w$
is the distance to the nearest wall.
These input features correspond to: the wall-distance-based Reynolds number (
 $q_1$
), the ratio of turbulent time scale to mean strain time scale (
$q_1$
), the ratio of turbulent time scale to mean strain time scale (
 $q_2$
), the ratio of total Reynolds stress to
$q_2$
), the ratio of total Reynolds stress to
 $k$
(
$k$
(
 $q_3$
) and different blending scalars used within the
$q_3$
) and different blending scalars used within the
 $k$
-
$k$
-
 $\omega$
SST model (
$\omega$
SST model (
 $q_4$
,
$q_4$
,
 $q_5$
,
$q_5$
,
 $q_6$
). The full list of integrity basis tensors is given in Appendix A. We use the first invariant (the trace,
$q_6$
). The full list of integrity basis tensors is given in Appendix A. We use the first invariant (the trace,
 $A_{\textit{ii}}$
) of the following tensors:
$A_{\textit{ii}}$
) of the following tensors:
 $B^{(1)}_{\textit{ij}}$
,
$B^{(1)}_{\textit{ij}}$
,
 $B^{(3)}_{\textit{ij}}$
,
$B^{(3)}_{\textit{ij}}$
,
 $B^{(4)}_{\textit{ij}}$
,
$B^{(4)}_{\textit{ij}}$
,
 $B^{(6)}_{\textit{ij}}$
,
$B^{(6)}_{\textit{ij}}$
,
 $B^{(7)}_{\textit{ij}}$
,
$B^{(7)}_{\textit{ij}}$
,
 $B^{(16)}_{\textit{ij}}$
and
$B^{(16)}_{\textit{ij}}$
and
 $B^{(35)}_{\textit{ij}}$
. We use the second invariant,
$B^{(35)}_{\textit{ij}}$
. We use the second invariant,
 ${1}/{2} ( (A_{\textit{ii}} )^2 - A_{\textit{ij}}A_{\textit{ji}} )$
, of the following tensors:
${1}/{2} ( (A_{\textit{ii}} )^2 - A_{\textit{ij}}A_{\textit{ji}} )$
, of the following tensors:
 $B^{(3)}_{\textit{ij}}$
,
$B^{(3)}_{\textit{ij}}$
,
 $B^{(6)}_{\textit{ij}}$
,
$B^{(6)}_{\textit{ij}}$
,
 $B^{(7)}_{\textit{ij}}$
,
$B^{(7)}_{\textit{ij}}$
,
 $B^{(8)}_{\textit{ij}}$
. These input features were hand picked from the full set of 94 invariants listed in Appendix A (Wu et al. Reference Wu, Xiao and Paterson2018; McConkey et al. Reference McConkey, Yee and Lien2022a
). As discussed in McConkey et al. (Reference McConkey, Yee and Lien2022a
), many of the invariants are zero for 2-D flows. However, different conditions cause different invariants to be zero. For example, in the present study, there are a different set of zero invariants for flow through over periodic hills, and flow through a square duct. This difference occurs because different components of
$B^{(8)}_{\textit{ij}}$
. These input features were hand picked from the full set of 94 invariants listed in Appendix A (Wu et al. Reference Wu, Xiao and Paterson2018; McConkey et al. Reference McConkey, Yee and Lien2022a
). As discussed in McConkey et al. (Reference McConkey, Yee and Lien2022a
), many of the invariants are zero for 2-D flows. However, different conditions cause different invariants to be zero. For example, in the present study, there are a different set of zero invariants for flow through over periodic hills, and flow through a square duct. This difference occurs because different components of
 $\partial () / \partial x_j$
are to be zero. We have performed a systematic investigation using a symbolic math toolbox (sympy (Meurer et al. Reference Meurer2017)) to determine which invariants are zero for the duct case, and general 2-D flows. We make the results and code available in Appendix A and on Github (McConkey Reference McConkey2023), respectively. Input features used in this investigation were selected based on the results in Appendix A. Therefore, the input features are not uniformly zero on any of the considered flows.
$\partial () / \partial x_j$
are to be zero. We have performed a systematic investigation using a symbolic math toolbox (sympy (Meurer et al. Reference Meurer2017)) to determine which invariants are zero for the duct case, and general 2-D flows. We make the results and code available in Appendix A and on Github (McConkey Reference McConkey2023), respectively. Input features used in this investigation were selected based on the results in Appendix A. Therefore, the input features are not uniformly zero on any of the considered flows.
To ensure all input features are of the same magnitude during training, they are scaled according to the following formula:
 \begin{equation} x^{{R}}_m = \frac {X^{{R}}_m - \mu _{m}}{\sigma _m} , \end{equation}
\begin{equation} x^{{R}}_m = \frac {X^{{R}}_m - \mu _{m}}{\sigma _m} , \end{equation}
where
 $x^{{R}}_m$
is the input feature vector for the neural network,
$x^{{R}}_m$
is the input feature vector for the neural network,
 $X^{{R}}_m$
is the raw input feature vector from the RANS simulation,
$X^{{R}}_m$
is the raw input feature vector from the RANS simulation,
 $\mu _m$
is a vector containing the mean of each input feature over the entire training dataset and
$\mu _m$
is a vector containing the mean of each input feature over the entire training dataset and
 $\sigma _{m}$
is a vector containing the standard deviation of each input feature over the entire training dataset.
$\sigma _{m}$
is a vector containing the standard deviation of each input feature over the entire training dataset.
When making predictions on the hold-out validation and test sets, the mean and standard deviation values from the training data are used to avoid data leakage.
1.5.3. Hyperparameters and training procedure
The hyperparameters for each neural network were hand tuned based on validation set performance. The hidden layers for all TBNNs and KCNNs are fully connected, feed-forward layers with Swish activation functions (Ramachandran, Zoph & Le Reference Ramachandran, Zoph and Le2017). The appropriate hyperparameters vary between flows, since each dataset contains a different number of data points, and the anisotropy mapping being learned is distinct. Table 2 shows the final hyperparameters used. All training runs used a mini-batch size of 32, except the periodic hill TBNN run, which used a mini-batch size of 128.
Table 2. Hyperparameters selected for each model.


Figure 8. Loss function vs epoch for the (a) TBNN and (b) KCNN models on the flat plate dataset; the (c) TBNN and (d) KCNN models on the square duct dataset; and the (e) TBNN and (f) KCNN models on the periodic hill dataset.
The AMSGrad Adam optimiser (Reddi, Kale & Kumar Reference Reddi, Kale and Kumar2018) was found to achieve better performance than the standard Adam optimiser (Kingma & Ba Reference Kingma and Ba2015) for training TBNNs. The learning rate and number of epochs for each optimiser is given in table 2. Satisfactory performance was achieved with a constant learning rate; for training on more complex flows we recommend the use of learning rate scheduling to achieve better performance. The training/validation loss curves for each model are shown in figure 8.
1.5.4. Hyperparameter tuning for TBKAN
The performance of the TBKAN was extensively optimised through a combination of systematic hyperparameter tuning and manual adjustments. The architecture of the TBKAN model was configured as
 $[6, 9, 10]$
, where 6 corresponds to the number of input features, 9 represents the network width (number of neurons per hidden layer) and 10 denotes the output size of the network. The depth of the network, representing the number of hidden layers, was fixed to 2 for the flat plate case.
$[6, 9, 10]$
, where 6 corresponds to the number of input features, 9 represents the network width (number of neurons per hidden layer) and 10 denotes the output size of the network. The depth of the network, representing the number of hidden layers, was fixed to 2 for the flat plate case.
Hyperparameter tuning focused on refining the grid size (
 $ g$
), network width (
$ g$
), network width (
 $ w$
), spline order and input feature combinations. An initial set of 27 runs, conducted with randomly selected configurations, broadly explored the hyperparameter space. These runs were used as a warm start for Bayesian optimisation, which further utilised 143 trials to systematically refine the hyperparameters. The configuration employed a grid size of 8 control points for the B-spline basis representation, with the polynomial order
$ w$
), spline order and input feature combinations. An initial set of 27 runs, conducted with randomly selected configurations, broadly explored the hyperparameter space. These runs were used as a warm start for Bayesian optimisation, which further utilised 143 trials to systematically refine the hyperparameters. The configuration employed a grid size of 8 control points for the B-spline basis representation, with the polynomial order
 $k$
of the splines fixed at a value of three (viz.,
$k$
of the splines fixed at a value of three (viz.,
 $k=3$
corresponding to cubic splines). This choice was found to provide the best balance between flexibility and computational efficiency.
$k=3$
corresponding to cubic splines). This choice was found to provide the best balance between flexibility and computational efficiency.
The final hyperparameters for the best-performing model were as follows: architecture
 $[6, 9, 10]$
, a depth of 2 layers, a grid size of 8 control points and a learning rate of
$[6, 9, 10]$
, a depth of 2 layers, a grid size of 8 control points and a learning rate of
 $ 4.9 \times 10^{-3}$
. This configuration achieved a mean-squared error (MSE) of 0.22 on the flat plate case. Input feature selection was refined by fixing three core features while sampling from a broader set to enhance the model’s adaptability in predicting finer details of the anisotropy tensor. The AMSGrad Adam optimiser (Reddi et al. Reference Reddi, Kale and Kumar2018) was used for all training runs, with a mini-batch size of 32, which ensured stable convergence. Training and validation loss curves for the best-performing model for the flat plate, corresponding to a KAN configuration with
$ 4.9 \times 10^{-3}$
. This configuration achieved a mean-squared error (MSE) of 0.22 on the flat plate case. Input feature selection was refined by fixing three core features while sampling from a broader set to enhance the model’s adaptability in predicting finer details of the anisotropy tensor. The AMSGrad Adam optimiser (Reddi et al. Reference Reddi, Kale and Kumar2018) was used for all training runs, with a mini-batch size of 32, which ensured stable convergence. Training and validation loss curves for the best-performing model for the flat plate, corresponding to a KAN configuration with
 $w=9$
,
$w=9$
,
 $g=8$
and
$g=8$
and
 $k=3$
(cubic splines), are shown in figure 9.
$k=3$
(cubic splines), are shown in figure 9.

Figure 9. Loss function vs epoch for the TBKAN model trained on the flat plate dataset, with the best-performing KAN configuration given by a network width of
 $w=9$
, a grid size of
$w=9$
, a grid size of
 $g=8$
and a polynomial order of
$g=8$
and a polynomial order of
 $k=3$
(cubic B-spline).
$k=3$
(cubic B-spline).
1.6. Computational costs
The inference-time cost for the proposed methodology varies significantly from case to case. A prediction requires (i) running a baseline RANS simulation, (ii) evaluating the Machine learning (ML) model predictions and (iii) running a corrected RANS simulation. Compared with steps (i) and (iii), the cost of step (ii) (model inference) is negligible. Additionally, since the converged fields from step (i) are used to initialise the simulation in step (iii), the cost of the corrected RANS simulation is also reduced. Generally, we found that combined inference-time costs for steps (i), (ii) and (iii) were between 1.5 and 3 times the cost of the baseline simulation (i.e. steps (i), (ii) and (iii) cost approximately 1.5–5 times as much as step (i)), depending on how much the injected closure fields differ from the original linear eddy viscosity-based field. The training cost also varies depending on the dataset. For the periodic hills and square duct datasets here, the training time was approximately 16 GPU hours on a single NVIDIA RTX 3090 GPU.
2. Results for proposed TBNN and TBKAN architectures
2.1. Generalisation tests
It was of interest to determine how well the trained models generalise to unseen variations of their training flows. This section demonstrates generalisation results for flow over a flat plate with zero pressure gradient, flow through a square duct and flow over periodic hills.
For all cases, the original RANS solution was generated using OpenFOAM v2212, assuming an isothermal, incompressible and Newtonian fluid. Simulation parameters such as solver, schemes and solution methodology for the zero pressure gradient flat plate case were identical to those discussed in McConkey et al. (Reference McConkey, Yee and Lien2021).
It should be noted that the
 $a_{\textit{ij}}$
predictions shown for the TBNN/KCNN use
$a_{\textit{ij}}$
predictions shown for the TBNN/KCNN use
 $S^\theta _{\textit{ij}}$
for predicting the linear part of the anisotropy tensor. The nature of the proposed TBNN training process is to utilise
$S^\theta _{\textit{ij}}$
for predicting the linear part of the anisotropy tensor. The nature of the proposed TBNN training process is to utilise
 $S^\theta _{\textit{ij}}$
during training, so that the remaining nonlinear part can be extracted during injection.
$S^\theta _{\textit{ij}}$
during training, so that the remaining nonlinear part can be extracted during injection.
2.1.1. Flat plate (TBNN)

Figure 10. Computational domain for the zero pressure gradient flat plate boundary layer case.
This case features a developing turbulent boundary layer on a flat plate with zero pressure gradient, based on the NASA ‘2DZP’ validation case (Rumsey Reference Rumsey2021). Figure 10 shows the domain for the flat plate case. The NASA-provided meshes are sufficient to resolve the viscous sublayer region, with a total number of cells
 $ N \approx 2\,00\,000$
. However, this mesh was further refined to increase the number of solution data points available for training and testing. The goal of this case is to learn how the anisotropy tensor evolves in a turbulent boundary layer, therefore substantial mesh refinement was required to generate data points in this region. The total number of cells in the mesh is
$ N \approx 2\,00\,000$
. However, this mesh was further refined to increase the number of solution data points available for training and testing. The goal of this case is to learn how the anisotropy tensor evolves in a turbulent boundary layer, therefore substantial mesh refinement was required to generate data points in this region. The total number of cells in the mesh is
 $N=4\,673\,130$
. The plate-length Reynolds number is
$N=4\,673\,130$
. The plate-length Reynolds number is
 ${\textit{Re}}_L= 5(10)^6$
to match the NASA reference data. The reference data for this case consist of a series of wall-normal profiles, for various
${\textit{Re}}_L= 5(10)^6$
to match the NASA reference data. The reference data for this case consist of a series of wall-normal profiles, for various
 ${\textit{Re}}_\theta$
, defined as
${\textit{Re}}_\theta$
, defined as
 \begin{equation} Re_\theta = \frac {U_\infty \theta }{\nu } , \end{equation}
\begin{equation} Re_\theta = \frac {U_\infty \theta }{\nu } , \end{equation}
where the momentum thickness
 $\theta$
is given as
$\theta$
is given as
 \begin{equation} \theta = \int _{0}^\infty \frac {U_{1}}{U_\infty } \left (1-\frac {U_1}{U_\infty }\right ) {\textrm{d}} x_2 , \end{equation}
\begin{equation} \theta = \int _{0}^\infty \frac {U_{1}}{U_\infty } \left (1-\frac {U_1}{U_\infty }\right ) {\textrm{d}} x_2 , \end{equation}
and
 $U_\infty$
is the free-stream velocity. The following boundary conditions and fluid properties are used for the domain in figure 10. At the inlet boundary,
$U_\infty$
is the free-stream velocity. The following boundary conditions and fluid properties are used for the domain in figure 10. At the inlet boundary,
 $U_{\!j}$
,
$U_{\!j}$
,
 $k$
and
$k$
and
 $\omega$
are uniform:
$\omega$
are uniform:
 $U_{\!j} = (69.4, 0, 0) {\textrm{m s}}^{-1}$
,
$U_{\!j} = (69.4, 0, 0) {\textrm{m s}}^{-1}$
,
 $k=1.08(10)^{-3} \ {\textrm{m}}^2\, {\textrm{s}}^{-2}$
,
$k=1.08(10)^{-3} \ {\textrm{m}}^2\, {\textrm{s}}^{-2}$
,
 $\omega = 8675 \ {\textrm{s}}^{-1}$
and
$\omega = 8675 \ {\textrm{s}}^{-1}$
and
 $P$
is zero normal gradient. At the outlet,
$P$
is zero normal gradient. At the outlet,
 $P$
is zero, and all other variables are zero normal gradient. At the symmetry plane, all variables are zero normal gradient, and normal velocity is zero. At the top plane, all flow variables are zero normal gradient. At the no-slip wall,
$P$
is zero, and all other variables are zero normal gradient. At the symmetry plane, all variables are zero normal gradient, and normal velocity is zero. At the top plane, all flow variables are zero normal gradient. At the no-slip wall,
 $U_{\!j}=0$
,
$U_{\!j}=0$
,
 $k=0$
,
$k=0$
,
 $\omega =6\nu /\beta _1 y^2$
(here,
$\omega =6\nu /\beta _1 y^2$
(here,
 $\beta _1=0.075$
) and
$\beta _1=0.075$
) and
 $P$
is zero normal gradient. A kinematic viscosity of
$P$
is zero normal gradient. A kinematic viscosity of
 $\nu = 1.388(10)^{-5} \ {\textrm{m}}\, {\textrm{s}}^{-2}$
was used.
$\nu = 1.388(10)^{-5} \ {\textrm{m}}\, {\textrm{s}}^{-2}$
was used.
The DNS reference data for a developing turbulent boundary layer come from Schlatter & Örlü (Reference Schlatter and Örlü2010). This dataset contains a variety of turbulent boundary layer profiles, at various
 ${\textit{Re}}_\theta$
shown in table 1. As discussed in § 1.5.1, the TBNN model was trained on various
${\textit{Re}}_\theta$
shown in table 1. As discussed in § 1.5.1, the TBNN model was trained on various
 ${\textit{Re}}_\theta$
, with
${\textit{Re}}_\theta$
, with
 ${\textit{Re}}_\theta =3630$
serving as a hold-out test case. The results shown in this section are for this hold-out test case.
${\textit{Re}}_\theta =3630$
serving as a hold-out test case. The results shown in this section are for this hold-out test case.
The baseline
 $k$
-
$k$
-
 $\omega$
SST model performs well for the test case flow in terms of predicting the mean velocity profiles. Figure 11 shows a sample mean velocity profile predicted by the baseline
$\omega$
SST model performs well for the test case flow in terms of predicting the mean velocity profiles. Figure 11 shows a sample mean velocity profile predicted by the baseline
 $k$
-
$k$
-
 $\omega$
SST model, and figure 12 shows the predicted evolution of
$\omega$
SST model, and figure 12 shows the predicted evolution of
 ${\textit{Re}}_\theta$
along the plate. The excellent performance of the
${\textit{Re}}_\theta$
along the plate. The excellent performance of the
 $k$
-
$k$
-
 $\omega$
SST model demonstrated by figures 11 and 12 is expected. This case features a fully attached boundary layer with zero pressure gradient, which is one of the fundamental calibration scenarios for RANS models. The zero pressure gradient turbulent boundary layer is considered a ‘solved problem’ for modern RANS models (Spalart Reference Spalart2023).
$\omega$
SST model demonstrated by figures 11 and 12 is expected. This case features a fully attached boundary layer with zero pressure gradient, which is one of the fundamental calibration scenarios for RANS models. The zero pressure gradient turbulent boundary layer is considered a ‘solved problem’ for modern RANS models (Spalart Reference Spalart2023).

Figure 11. Streamwise velocity profile in the
 ${\textit{Re}}_\theta =3630$
boundary layer predicted by the
${\textit{Re}}_\theta =3630$
boundary layer predicted by the
 $k$
-
$k$
-
 $\omega$
SST model, compared with the reference data from Schlatter & Örlü (Reference Schlatter and Örlü2010). Here,
$\omega$
SST model, compared with the reference data from Schlatter & Örlü (Reference Schlatter and Örlü2010). Here,
 $U^+_1 = U^{}_1/u_\tau$
, where
$U^+_1 = U^{}_1/u_\tau$
, where
 $u_\tau =\sqrt {\tau _w/\rho }$
is the friction velocity, and
$u_\tau =\sqrt {\tau _w/\rho }$
is the friction velocity, and
 $\tau _w$
is the wall shear stress. A density of
$\tau _w$
is the wall shear stress. A density of
 $1$
kg m−
$1$
kg m−
 $^3$
was used to be consistent with OpenFOAM’s kinematic units. The wall-normal coordinate is
$^3$
was used to be consistent with OpenFOAM’s kinematic units. The wall-normal coordinate is
 $y^+=x_2u_\tau /\nu$
.
$y^+=x_2u_\tau /\nu$
.

Figure 12. Momentum thickness Reynolds number growth along the flat plate as predicted by the
 $k$
-
$k$
-
 $\omega$
SST model, and the reference DNS data from Schlatter & Örlü (Reference Schlatter and Örlü2010).
$\omega$
SST model, and the reference DNS data from Schlatter & Örlü (Reference Schlatter and Örlü2010).
While the mean velocity profile is predicted well, figure 13 shows that the evolution of the near-wall anisotropy tensor is not predicted well. For this reason, the model architecture discussed in § 1.4 was used to correct the anisotropy tensor in the near-wall region. This test also aims to determine whether the input feature set is sufficiently expressive to enable predicting the evolution of the anisotropy tensor within a boundary layer. Figure 13 shows the wall-normal profiles of various anisotropy tensor components predicted by the
 $k$
-
$k$
-
 $\omega$
SST model, the ML-augmented
$\omega$
SST model, the ML-augmented
 $k$
-
$k$
-
 $\omega$
SST model and the reference DNS simulation for the hold-out test case. As discussed in § 1.5.1, these models were trained on flat plate data at various values of
$\omega$
SST model and the reference DNS simulation for the hold-out test case. As discussed in § 1.5.1, these models were trained on flat plate data at various values of
 ${\textit{Re}}_\theta$
. The results in figure 13 are designed to test these models on input features from an unseen boundary layer profile, to determine whether the learned anisotropy mapping was generalisable.
${\textit{Re}}_\theta$
. The results in figure 13 are designed to test these models on input features from an unseen boundary layer profile, to determine whether the learned anisotropy mapping was generalisable.

Figure 13. Evolution of (a)
 $a_{11}$
, (b)
$a_{11}$
, (b)
 $a_{12}$
, (c)
$a_{12}$
, (c)
 $a_{22}$
and (d)
$a_{22}$
and (d)
 $a_{33}$
in the
$a_{33}$
in the
 ${\textit{Re}}_\theta = 3630$
boundary layer, as predicted by the DNS data from Schlatter & Örlü (Reference Schlatter and Örlü2010), the TBNN/KCNN model and the baseline
${\textit{Re}}_\theta = 3630$
boundary layer, as predicted by the DNS data from Schlatter & Örlü (Reference Schlatter and Örlü2010), the TBNN/KCNN model and the baseline
 $k$
-
$k$
-
 $\omega$
SST model.
$\omega$
SST model.

Figure 14. Evolution of (a)
 $a_{11}$
, (b)
$a_{11}$
, (b)
 $a_{12}$
, (c)
$a_{12}$
, (c)
 $a_{22}$
and (d)
$a_{22}$
and (d)
 $a_{33}$
in the
$a_{33}$
in the
 ${\textit{Re}}_\theta = 3630$
boundary layer, as predicted by the DNS data from Schlatter & Örlü (Reference Schlatter and Örlü2010), the TBKAN/KCNN model and the baseline
${\textit{Re}}_\theta = 3630$
boundary layer, as predicted by the DNS data from Schlatter & Örlü (Reference Schlatter and Örlü2010), the TBKAN/KCNN model and the baseline
 $k$
-
$k$
-
 $\omega$
SST model.
$\omega$
SST model.
Figure 13(a) shows the predicted evolution of
 $a_{11}$
in the turbulent boundary layer. The baseline
$a_{11}$
in the turbulent boundary layer. The baseline
 $k$
-
$k$
-
 $\omega$
SST model predicts
$\omega$
SST model predicts
 $a_{11}=0$
, since
$a_{11}=0$
, since
 $\partial U_1 /\partial x_1 \approx 0$
in the boundary layer. However, the DNS data clearly show that
$\partial U_1 /\partial x_1 \approx 0$
in the boundary layer. However, the DNS data clearly show that
 $a_{11}$
is non-zero in the boundary layer. The TBNN/KCNN model combination is able to correct the
$a_{11}$
is non-zero in the boundary layer. The TBNN/KCNN model combination is able to correct the
 $a_{11}$
term to a high degree of accuracy in the boundary layer on this test case, indicating that the anisotropy mapping for the
$a_{11}$
term to a high degree of accuracy in the boundary layer on this test case, indicating that the anisotropy mapping for the
 $a_{11}$
component generalises well. Similar evolutions of
$a_{11}$
component generalises well. Similar evolutions of
 $a_{22}$
(figure 13
c) and
$a_{22}$
(figure 13
c) and
 $a_{33}$
(figure 13
d) are observed in the DNS data. Again, the
$a_{33}$
(figure 13
d) are observed in the DNS data. Again, the
 $k$
-
$k$
-
 $\omega$
SST model predicts
$\omega$
SST model predicts
 $a_{11}=a_{22}=a_{33}=0$
, which is not physically correct. The TBNN/KCNN models are able to correct the baseline prediction to a high degree of accuracy on this unseen boundary layer profile.
$a_{11}=a_{22}=a_{33}=0$
, which is not physically correct. The TBNN/KCNN models are able to correct the baseline prediction to a high degree of accuracy on this unseen boundary layer profile.
Figure 13(b) shows the predicted evolution of
 $a_{12}$
. The baseline RANS model predicts the evolution of
$a_{12}$
. The baseline RANS model predicts the evolution of
 $a_{12}$
well, and this is likely the reason that the mean velocity profile of
$a_{12}$
well, and this is likely the reason that the mean velocity profile of
 $U_{1}$
is predicted well (see figure 11). While the TBNN/KCNN is not needed to correct this off-diagonal component, it is able to correct minor inaccuracies in the
$U_{1}$
is predicted well (see figure 11). While the TBNN/KCNN is not needed to correct this off-diagonal component, it is able to correct minor inaccuracies in the
 $k$
-
$k$
-
 $\omega$
SST model predictions in the buffer region (
$\omega$
SST model predictions in the buffer region (
 $5 \leqslant y^+ \leqslant 30$
). Nevertheless, the baseline
$5 \leqslant y^+ \leqslant 30$
). Nevertheless, the baseline
 $k$
-
$k$
-
 $\omega$
SST model achieves a satisfactory accuracy level for this flow. As discussed, this is expected, given that low Reynolds number RANS models are able to predict a zero pressure gradient boundary layer with a high degree of accuracy. Figure 13 demonstrates that this performance is the result of an accurate prediction of
$\omega$
SST model achieves a satisfactory accuracy level for this flow. As discussed, this is expected, given that low Reynolds number RANS models are able to predict a zero pressure gradient boundary layer with a high degree of accuracy. Figure 13 demonstrates that this performance is the result of an accurate prediction of
 $a_{12}$
by the
$a_{12}$
by the
 $k$
-
$k$
-
 $\omega$
SST model.
$\omega$
SST model.
2.1.2. Flat plate (TBKAN)
The predicted evolution of the various components of the anisotropy tensor for the flat plate case obtained using the TBKAN/KCNN model combination is displayed in figure 14(a)–14(d) for the hold-out test case
 ${\textit{Re}}_\theta = 3630$
. These predictions are compared with both the baseline
${\textit{Re}}_\theta = 3630$
. These predictions are compared with both the baseline
 $k$
-
$k$
-
 $\omega$
SST model and DNS data from Schlatter & Örlü (2010). For this test case, the predictive accuracy of the TBKAN/KCNN model combination for the anisotropy tensor components is compared with that of the baseline model.
$\omega$
SST model and DNS data from Schlatter & Örlü (2010). For this test case, the predictive accuracy of the TBKAN/KCNN model combination for the anisotropy tensor components is compared with that of the baseline model.
The predicted evolution of
 $a_{11}$
is shown in figure 14(a). Unlike the
$a_{11}$
is shown in figure 14(a). Unlike the
 $k$
-
$k$
-
 $\omega$
SST model, which predicts
$\omega$
SST model, which predicts
 $a_{11}=0$
due to its linear stress assumptions, the TBKAN captures the non-zero nature of
$a_{11}=0$
due to its linear stress assumptions, the TBKAN captures the non-zero nature of
 $a_{11}$
in the turbulent boundary layer. The TBKAN aligns closely with the DNS data, indicating its ability to generalise and represent anisotropy accurately, particularly for components where the baseline model is limited.
$a_{11}$
in the turbulent boundary layer. The TBKAN aligns closely with the DNS data, indicating its ability to generalise and represent anisotropy accurately, particularly for components where the baseline model is limited.
Figure 14(b) presents the predicted evolution of
 $a_{12}$
. The baseline
$a_{12}$
. The baseline
 $k$
-
$k$
-
 $\omega$
SST model predicts this off-diagonal component with reasonable accuracy. However, the TBKAN/KCNN exhibits better conformance with the reference DNS data in the buffer region (
$\omega$
SST model predicts this off-diagonal component with reasonable accuracy. However, the TBKAN/KCNN exhibits better conformance with the reference DNS data in the buffer region (
 $5 \leqslant y^+ \leqslant 30$
), correcting minor deviations in the predictions of this quantity provided by the baseline
$5 \leqslant y^+ \leqslant 30$
), correcting minor deviations in the predictions of this quantity provided by the baseline
 $k$
-
$k$
-
 $\omega$
SST model.
$\omega$
SST model.
Figures 14(c) and 14(d) display the predictions of
 $a_{22}$
and
$a_{22}$
and
 $a_{33}$
, respectively. While the
$a_{33}$
, respectively. While the
 $k$
-
$k$
-
 $\omega$
SST model predicts a value of zero from these two anisotropy stress components, the TBKAN/KCNN captures their evolution with good accuracy compared with the DNS data. Overall, TBKAN/KCNN enhances the predictive accuracy of the anisotropic stress components across the boundary layer. While
$\omega$
SST model predicts a value of zero from these two anisotropy stress components, the TBKAN/KCNN captures their evolution with good accuracy compared with the DNS data. Overall, TBKAN/KCNN enhances the predictive accuracy of the anisotropic stress components across the boundary layer. While
 $a_{12}$
predictions are marginally improved compared with the baseline model, TBKAN/KCNN shows substantial improvements for the normal stress components. Furthermore, a visual perusal of figures 13 and 14 shows that the conformance of the predictions of the anisotropy tensor components with the reference DNS data obtained with TBKAN/KCNN is marginally worse than that obtained with TBNN/KCNN. However, it is noted that the TBKAN is simpler than TBNN in this case in the sense that the former network used only one hidden layer with 9 nodes (where the information from the edges encoded in the B-splines are simply accumulated), whereas the latter network used four hidden layers consisting of 20 nodes each (where the information embodied by the linear weights in the edges is transformed by the nonlinear activation function).
$a_{12}$
predictions are marginally improved compared with the baseline model, TBKAN/KCNN shows substantial improvements for the normal stress components. Furthermore, a visual perusal of figures 13 and 14 shows that the conformance of the predictions of the anisotropy tensor components with the reference DNS data obtained with TBKAN/KCNN is marginally worse than that obtained with TBNN/KCNN. However, it is noted that the TBKAN is simpler than TBNN in this case in the sense that the former network used only one hidden layer with 9 nodes (where the information from the edges encoded in the B-splines are simply accumulated), whereas the latter network used four hidden layers consisting of 20 nodes each (where the information embodied by the linear weights in the edges is transformed by the nonlinear activation function).
2.1.3. Square duct
Turbulent flow through a square duct is a challenging case for RANS models, since linear eddy viscosity models cannot predict the secondary flows that occur in the cross-sectional plane. The goal of the square duct test case is to determine whether the proposed closure framework could enable the
 $k$
-
$k$
-
 $\omega$
SST model to predict these Prandtl secondary flows (Nikitin, Popelenskaya & Stroh Reference Nikitin, Popelenskaya and Stroh2021). The square duct DNS dataset generated by Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010) was used as reference data, and the RANS data from McConkey et al. (Reference McConkey, Yee and Lien2021) was used.
$\omega$
SST model to predict these Prandtl secondary flows (Nikitin, Popelenskaya & Stroh Reference Nikitin, Popelenskaya and Stroh2021). The square duct DNS dataset generated by Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010) was used as reference data, and the RANS data from McConkey et al. (Reference McConkey, Yee and Lien2021) was used.

Figure 15. Computational (a) domain and (b) RANS mesh for the square duct flow.
Figure 15 shows the computational set-up and mesh for the square duct case. The mesh is designed to achieve
 $y^+\leqslant 1$
for all square duct cases. As discussed in § 1.5.1, the duct half-height
$y^+\leqslant 1$
for all square duct cases. As discussed in § 1.5.1, the duct half-height
 $H$
Reynolds number varies between cases, calculated by
$H$
Reynolds number varies between cases, calculated by
 \begin{equation} Re_H = \frac {U_b H}{\nu } , \end{equation}
\begin{equation} Re_H = \frac {U_b H}{\nu } , \end{equation}
where
 $U_b$
is the mean (bulk) cross-sectional velocity. A kinematic viscosity of
$U_b$
is the mean (bulk) cross-sectional velocity. A kinematic viscosity of
 $\nu =5(10)^{-6}$
m
$\nu =5(10)^{-6}$
m
 $^2$
s−1 was used for all square duct cases. With the geometry fixed as shown in figure 15, the bulk velocity was adjusted to vary the Reynolds number. More details on the computational set-up for the square duct case are provided by McConkey et al. (Reference McConkey, Yee and Lien2021). The boundary conditions are periodic at the inlet/outlet, and no-slip walls were applied along the sides of the duct. As discussed in § 1.5.1, the modified TBNN was trained on several values of
$^2$
s−1 was used for all square duct cases. With the geometry fixed as shown in figure 15, the bulk velocity was adjusted to vary the Reynolds number. More details on the computational set-up for the square duct case are provided by McConkey et al. (Reference McConkey, Yee and Lien2021). The boundary conditions are periodic at the inlet/outlet, and no-slip walls were applied along the sides of the duct. As discussed in § 1.5.1, the modified TBNN was trained on several values of
 ${\textit{Re}}_{\!H}$
, with
${\textit{Re}}_{\!H}$
, with
 ${\textit{Re}}_{\!H} = 2000$
serving as a hold-out test case.
${\textit{Re}}_{\!H} = 2000$
serving as a hold-out test case.

Figure 16. Components of
 $a_{\textit{ij}}$
predicted by the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010), the
$a_{\textit{ij}}$
predicted by the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010), the
 $k$
-
$k$
-
 $\omega$
SST model, and the TBNN/KCNN model from the present investigation. Shown here are contours of
$\omega$
SST model, and the TBNN/KCNN model from the present investigation. Shown here are contours of
 $a_{\textit{ij}}$
components in the lower left
$a_{\textit{ij}}$
components in the lower left
 $x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
$x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
Figure 16 shows the components of the anisotropy tensor
 $a_{\textit{ij}}$
predicted by RANS, DNS and the TBNN/KCNN models for the square duct test case. The
$a_{\textit{ij}}$
predicted by RANS, DNS and the TBNN/KCNN models for the square duct test case. The
 $k$
-
$k$
-
 $\omega$
SST model is a linear eddy viscosity model, and therefore predicts zero
$\omega$
SST model is a linear eddy viscosity model, and therefore predicts zero
 $a_{\textit{ij}}$
where
$a_{\textit{ij}}$
where
 $S_{\textit{ij}}$
is zero. Figure 16 shows that
$S_{\textit{ij}}$
is zero. Figure 16 shows that
 $a_{11}$
,
$a_{11}$
,
 $a_{22}$
,
$a_{22}$
,
 $a_{23}$
and
$a_{23}$
and
 $a_{33}$
are all non-zero in the duct, and that the
$a_{33}$
are all non-zero in the duct, and that the
 $k$
-
$k$
-
 $\omega$
SST model is unable to capture this behaviour. The TBNN/KCNN models predict an accurate evolution of almost all anisotropy tensor components across the duct cross-section (viz.
$\omega$
SST model is unable to capture this behaviour. The TBNN/KCNN models predict an accurate evolution of almost all anisotropy tensor components across the duct cross-section (viz.
 $a_{11}$
,
$a_{11}$
,
 $a_{12}$
,
$a_{12}$
,
 $a_{13}$
,
$a_{13}$
,
 $a_{22}$
and
$a_{22}$
and
 $a_{33}$
are all predicted well on this test case). The anisotropy tensor component
$a_{33}$
are all predicted well on this test case). The anisotropy tensor component
 $a_{23}$
is not predicted well, likely because it is at least an order of magnitude smaller than the other components, and therefore errors in
$a_{23}$
is not predicted well, likely because it is at least an order of magnitude smaller than the other components, and therefore errors in
 $a_{23}$
are not penalised as heavily in the loss function.
$a_{23}$
are not penalised as heavily in the loss function.
Figure 17 shows the turbulent kinetic energy
 $k$
after being corrected by the KCNN model for the square duct test case. Accurate prediction of
$k$
after being corrected by the KCNN model for the square duct test case. Accurate prediction of
 $k$
is critical to an accurate estimate of
$k$
is critical to an accurate estimate of
 $a_{\textit{ij}}$
, since
$a_{\textit{ij}}$
, since
 $a_{\textit{ij}}=2kb_{\textit{ij}}$
. The
$a_{\textit{ij}}=2kb_{\textit{ij}}$
. The
 $k$
-
$k$
-
 $\omega$
SST model generally under-predicts
$\omega$
SST model generally under-predicts
 $k$
. After correction via the KCNN, the
$k$
. After correction via the KCNN, the
 $k$
field is predicted well compared with the DNS data. The primary feature in the
$k$
field is predicted well compared with the DNS data. The primary feature in the
 $k$
field that is absent from the
$k$
field that is absent from the
 $k$
-
$k$
-
 $\omega$
SST prediction is the high-
$\omega$
SST prediction is the high-
 $k$
region along the sidewalls of the duct. The KCNN introduces a correction to the baseline RANS field, and is able to predict this high-
$k$
region along the sidewalls of the duct. The KCNN introduces a correction to the baseline RANS field, and is able to predict this high-
 $k$
region.
$k$
region.

Figure 17. Contours of turbulent kinetic energy
 $k$
predicted by (a) the
$k$
predicted by (a) the
 $k$
-
$k$
-
 $\omega$
SST model, (b) the KCNN in the present investigation and (c) the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010). Shown here is the lower left
$\omega$
SST model, (b) the KCNN in the present investigation and (c) the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010). Shown here is the lower left
 $x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
$x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
Ultimately, it is the goal of the proposed framework to improve the estimated mean fields in the RANS simulation. To determine whether the corrected closure term would produce corrected mean velocity fields, the predicted
 $\tilde a^{\perp}_{\textit{ij}}$
was injected into the RANS momentum equation as shown in (1.15). The momentum and continuity equations converged around the fixed
$\tilde a^{\perp}_{\textit{ij}}$
was injected into the RANS momentum equation as shown in (1.15). The momentum and continuity equations converged around the fixed
 $\tilde a^{\perp}_{\textit{ij}}$
until numerical convergence was achieved. In OpenFOAM v2212, a modified version of the Pressure implicit splitting of operators - semi implicit method for pressure linked equations (PIMPLE) solver was implemented for the purpose of this injection. The PIMPLE solver was used to incorporate an unsteady term into the system of equations during iteration, to promote stability. Although this unsteady term affects the solution during convergence, the simulation ultimately achieved a steady-state condition, thereby reducing this unsteady term to zero.
$\tilde a^{\perp}_{\textit{ij}}$
until numerical convergence was achieved. In OpenFOAM v2212, a modified version of the Pressure implicit splitting of operators - semi implicit method for pressure linked equations (PIMPLE) solver was implemented for the purpose of this injection. The PIMPLE solver was used to incorporate an unsteady term into the system of equations during iteration, to promote stability. Although this unsteady term affects the solution during convergence, the simulation ultimately achieved a steady-state condition, thereby reducing this unsteady term to zero.
Figure 18 shows that the TBNN/KCNN model is able to produce secondary flows after injecting
 $\tilde a^{\perp}_{\textit{ij}}$
into the momentum equation. This a posteriori prediction of the mean field is ultimately the main prediction of interest for a ML-augmented RANS closure framework. Whereas the original
$\tilde a^{\perp}_{\textit{ij}}$
into the momentum equation. This a posteriori prediction of the mean field is ultimately the main prediction of interest for a ML-augmented RANS closure framework. Whereas the original
 $k$
-
$k$
-
 $\omega$
SST model does not predict formation of any secondary flows in the duct, figure 18 shows that the ML-augmented
$\omega$
SST model does not predict formation of any secondary flows in the duct, figure 18 shows that the ML-augmented
 $k$
-
$k$
-
 $\omega$
SST model predicts corner vortices. However, the in-plane kinetic energy is generally underpredicted by the ML-augmented RANS model.
$\omega$
SST model predicts corner vortices. However, the in-plane kinetic energy is generally underpredicted by the ML-augmented RANS model.

Figure 18. Velocity vectors and in-plane kinetic energy predicted by (a) the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010), (b) the
 $k$
-
$k$
-
 $\omega$
SST model and (c) injecting the TBNN/KCNN predictions into the RANS momentum equations. Shown here is the lower left
$\omega$
SST model and (c) injecting the TBNN/KCNN predictions into the RANS momentum equations. Shown here is the lower left
 $x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
$x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
To further examine the ability of the ML-augmented
 $k$
-
$k$
-
 $\omega$
SST model to predict secondary flows in the duct test case, profiles of
$\omega$
SST model to predict secondary flows in the duct test case, profiles of
 $U_2$
and
$U_2$
and
 $U_3$
are plotted in figure 19. While the ML-augmented model is able to produce this nonlinear feature, the corner vortex strengths are reduced compared with the reference DNS data. Both the
$U_3$
are plotted in figure 19. While the ML-augmented model is able to produce this nonlinear feature, the corner vortex strengths are reduced compared with the reference DNS data. Both the
 $U_2$
and
$U_2$
and
 $U_3$
components are under-predicted. Nevertheless, the
$U_3$
components are under-predicted. Nevertheless, the
 $k$
-
$k$
-
 $\omega$
SST model (which predicts
$\omega$
SST model (which predicts
 $U_2=U_3=0$
) has clearly been improved via a ML-augmented correction to the closure term in the momentum equation. From figure 16, it would appear that the good prediction of the normal stress anisotropy (the primary mechanism responsible for the streamwise vorticity determined by
$U_2=U_3=0$
) has clearly been improved via a ML-augmented correction to the closure term in the momentum equation. From figure 16, it would appear that the good prediction of the normal stress anisotropy (the primary mechanism responsible for the streamwise vorticity determined by
 $U_2$
and
$U_2$
and
 $U_3$
) should provide good predictions of the streamwise vorticity. However, once the secondary flow is set in motion by this normal stress anisotropy, it is the secondary (rather than primary) shear stress component
$U_3$
) should provide good predictions of the streamwise vorticity. However, once the secondary flow is set in motion by this normal stress anisotropy, it is the secondary (rather than primary) shear stress component
 $a_{23}$
(generated by the presence of the secondary flow itself) that is required to maintain this flow and from figure 16, this secondary component of the shear stress is not well predicted. Therefore, the underprediction of
$a_{23}$
(generated by the presence of the secondary flow itself) that is required to maintain this flow and from figure 16, this secondary component of the shear stress is not well predicted. Therefore, the underprediction of
 $U_2$
and
$U_2$
and
 $U_3$
is likely due to inaccurate prediction of
$U_3$
is likely due to inaccurate prediction of
 $a_{23}$
.
$a_{23}$
.

Figure 19. Profiles of the in-plane velocity components (a)
 $U_2$
and (b)
$U_2$
and (b)
 $U_3$
, as predicted by the
$U_3$
, as predicted by the
 $k$
-
$k$
-
 $\omega$
SST model, the injected TBNN/KCNN predictions and the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010). Shown here is the lower left
$\omega$
SST model, the injected TBNN/KCNN predictions and the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010). Shown here is the lower left
 $x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
$x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
2.1.4. Rectangular duct test case
Duct aspect ratio has an influence on the in-plane kinetic energy
 ${1}/{2} (U_2^2+U_3^2 )$
and behaviour of the corner vortices (Vinuesa et al. Reference Vinuesa, Noorani, Lozano-Durán, Khoury, Schlatter, Fischer and Nagib2014, Reference Vinuesa, Schlatter and Nagib2015, Reference Vinuesa, Prus, Schlatter and Nagib2016). It was of interest to examine the ability of a model trained on square ducts to generalise to a rectangular duct at similar Reynolds number. The TBNN/KCNN models were applied to a duct with aspect ratio 3 and
${1}/{2} (U_2^2+U_3^2 )$
and behaviour of the corner vortices (Vinuesa et al. Reference Vinuesa, Noorani, Lozano-Durán, Khoury, Schlatter, Fischer and Nagib2014, Reference Vinuesa, Schlatter and Nagib2015, Reference Vinuesa, Prus, Schlatter and Nagib2016). It was of interest to examine the ability of a model trained on square ducts to generalise to a rectangular duct at similar Reynolds number. The TBNN/KCNN models were applied to a duct with aspect ratio 3 and
 ${\textit{Re}}_{\!H}\approx 2600$
, matching the DNS simulation by Vinuesa, Schlatter & Nagib (Reference Vinuesa, Schlatter and Nagib2018). This generalisation test was carried out in the same manner as the
${\textit{Re}}_{\!H}\approx 2600$
, matching the DNS simulation by Vinuesa, Schlatter & Nagib (Reference Vinuesa, Schlatter and Nagib2018). This generalisation test was carried out in the same manner as the
 ${\textit{Re}}_{\!H}=2000$
hold-out test case (i.e. by making a predictive correction to the closure terms in the
${\textit{Re}}_{\!H}=2000$
hold-out test case (i.e. by making a predictive correction to the closure terms in the
 $k$
-
$k$
-
 $\omega$
SST turbulence model, and injecting them back into the momentum equation).
$\omega$
SST turbulence model, and injecting them back into the momentum equation).

Figure 20. Velocity vectors and in-plane kinetic energy predicted by (a) the DNS data from Pinelli et al. (Reference Pinelli, Uhlmann, Sekimoto and Kawahara2010), (b) the
 $k$
-
$k$
-
 $\omega$
SST model and (c) injecting the TBNN/KCNN predictions into the RANS momentum equations. Shown here is the lower left
$\omega$
SST model and (c) injecting the TBNN/KCNN predictions into the RANS momentum equations. Shown here is the lower left
 $x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
$x_2\leqslant 0, \ x_3\leqslant 0$
quadrant.
Figure 20 compares the in-plane kinetic energy and velocity vector field predicted by the baseline
 $k$
-
$k$
-
 $\omega$
SST model, and the TBNN/KCNN augmented
$\omega$
SST model, and the TBNN/KCNN augmented
 $k$
-
$k$
-
 $\omega$
SST model. Examining figure 20 shows that ML-based correction enables the augmented SST model to predict secondary flows. However, in the same manner as the square duct test case, the in-plane kinetic energy is underpredicted. Additionally, the strength of the dominant corner vortex is over-predicted by the ML-augmented model, while the strength of the smaller corner vortex is significantly underpredicted. The magnitude of the in-plane kinetic energy is similar, however, the peak locations of this field are also shifted due to a mismatch in predicted corner vortex shape. Nevertheless, the ML-augmented model shows improvement compared with the
$\omega$
SST model. Examining figure 20 shows that ML-based correction enables the augmented SST model to predict secondary flows. However, in the same manner as the square duct test case, the in-plane kinetic energy is underpredicted. Additionally, the strength of the dominant corner vortex is over-predicted by the ML-augmented model, while the strength of the smaller corner vortex is significantly underpredicted. The magnitude of the in-plane kinetic energy is similar, however, the peak locations of this field are also shifted due to a mismatch in predicted corner vortex shape. Nevertheless, the ML-augmented model shows improvement compared with the
 $k$
-
$k$
-
 $\omega$
SST model, which fails to predict any corner vortices. In order to promote better generalisation to rectangular geometries, a more extensive training dataset consisting of rectangular ducts would need to be used to train the models.
$\omega$
SST model, which fails to predict any corner vortices. In order to promote better generalisation to rectangular geometries, a more extensive training dataset consisting of rectangular ducts would need to be used to train the models.
2.1.5. Periodic hills
Flow over periodic hills is used as a popular benchmark case for turbulence modelling given the challenging physics of boundary layer separation in an adverse pressure gradient, reattachment along the bottom wall, and acceleration of the flow before re-entering the domain. For the purpose of data-driven turbulence modelling, a variety of periodic hill data have been made available. In this study, we use the
 ${\textit{Re}}_{\!H}=5600$
configuration, simulated using DNS by Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020). Xiao et al.’s data were included in McConkey et al. (Reference McConkey, Yee and Lien2021), which is the primary data source for this study.
${\textit{Re}}_{\!H}=5600$
configuration, simulated using DNS by Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020). Xiao et al.’s data were included in McConkey et al. (Reference McConkey, Yee and Lien2021), which is the primary data source for this study.

Figure 21. Computational domain and mesh for the periodic hill case, with
 $\alpha =1.2$
.
$\alpha =1.2$
.
The geometry and mesh for the periodic hill case are shown in figure 21. For all periodic hill cases, the hill height-based Reynolds number is 5600, calculated by
 \begin{equation} Re_H = \frac {U_b H}{\nu } , \end{equation}
\begin{equation} Re_H = \frac {U_b H}{\nu } , \end{equation}
where
 $U_b$
is the bulk (mean) velocity at the domain inlet. The hill geometry is varied between cases, based on the hill steepness
$U_b$
is the bulk (mean) velocity at the domain inlet. The hill geometry is varied between cases, based on the hill steepness
 $\alpha$
. Further details on the computational set-up for the baseline RANS periodic hill simulations are provided in McConkey et al. (Reference McConkey, Yee and Lien2021). The boundary conditions are periodic at the inlet/outlet, and no-slip walls at the top and bottom of the domain were imposed. As discussed in § 1.5.1, the TBNN and KCNN models were trained on several hill steepness values, with
$\alpha$
. Further details on the computational set-up for the baseline RANS periodic hill simulations are provided in McConkey et al. (Reference McConkey, Yee and Lien2021). The boundary conditions are periodic at the inlet/outlet, and no-slip walls at the top and bottom of the domain were imposed. As discussed in § 1.5.1, the TBNN and KCNN models were trained on several hill steepness values, with
 $\alpha =1.2$
being used as a hold-out test set.
$\alpha =1.2$
being used as a hold-out test set.

Figure 22. Contours of non-zero
 $a_{\textit{ij}}$
components predicted by the DNS data from Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020), the
$a_{\textit{ij}}$
components predicted by the DNS data from Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020), the
 $k$
-
$k$
-
 $\omega$
SST model and the TBNN/KCNN model predictions from the present investigation.
$\omega$
SST model and the TBNN/KCNN model predictions from the present investigation.
Figure 22 shows the components of the anisotropy tensor
 $a_{\textit{ij}}$
predicted by RANS (
$a_{\textit{ij}}$
predicted by RANS (
 $k$
-
$k$
-
 $\omega$
SST), DNS and the ML-augmented RANS simulation. The improvement in all components of
$\omega$
SST), DNS and the ML-augmented RANS simulation. The improvement in all components of
 $a_{\textit{ij}}$
is clear. The baseline
$a_{\textit{ij}}$
is clear. The baseline
 $k$
-
$k$
-
 $\omega$
SST model under-predicts all components, with severe under-prediction of
$\omega$
SST model under-predicts all components, with severe under-prediction of
 $a_{11}$
,
$a_{11}$
,
 $a_{22}$
and
$a_{22}$
and
 $a_{33}$
. The
$a_{33}$
. The
 $a_{12}$
prediction by the
$a_{12}$
prediction by the
 $k$
-
$k$
-
 $\omega$
SST model showcases similar trends to the DNS data, but the overall magnitude is lower. However, after correction, key features of all
$\omega$
SST model showcases similar trends to the DNS data, but the overall magnitude is lower. However, after correction, key features of all
 $a_{\textit{ij}}$
fields are captured when the TBNN/KCNN augment the
$a_{\textit{ij}}$
fields are captured when the TBNN/KCNN augment the
 $k$
-
$k$
-
 $\omega$
SST model. In particular, the higher magnitudes of the diagonal
$\omega$
SST model. In particular, the higher magnitudes of the diagonal
 $a_{\textit{ij}}$
(normal stress) components are captured by the augmented model.
$a_{\textit{ij}}$
(normal stress) components are captured by the augmented model.

Figure 23. Contours of
 $U_1$
and
$U_1$
and
 $U_1$
predicted by the DNS data from Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020), the
$U_1$
predicted by the DNS data from Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020), the
 $k$
-
$k$
-
 $\omega$
SST model and the injected TBNN/KCNN model predictions from the present investigation.
$\omega$
SST model and the injected TBNN/KCNN model predictions from the present investigation.

Figure 24. Contours of error in
 $U_1$
and
$U_1$
and
 $U_2$
predicted by the
$U_2$
predicted by the
 $k$
-
$k$
-
 $\omega$
SST model and the injected TBNN/KCNN model predictions, as compared with the DNS data from Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020).
$\omega$
SST model and the injected TBNN/KCNN model predictions, as compared with the DNS data from Xiao et al. (Reference Xiao, Wu, Laizet and Duan2020).
As was done for the square duct test case (§ 2.1.3), a modified PIMPLE solver was used to inject the predicted
 $\tilde a_{\textit{ij}}$
into the RANS momentum equation for the periodic hill test case. The numerical set-up for the periodic hill injection was identical to the square duct case. Figure 23 compares the mean velocity fields before and after the corrected closure term is used within the RANS simulation. Figure 24 compares the errors in the velocity components
$\tilde a_{\textit{ij}}$
into the RANS momentum equation for the periodic hill test case. The numerical set-up for the periodic hill injection was identical to the square duct case. Figure 23 compares the mean velocity fields before and after the corrected closure term is used within the RANS simulation. Figure 24 compares the errors in the velocity components
 $U_1$
and
$U_1$
and
 $U_2$
estimated by the
$U_2$
estimated by the
 $k$
-
$k$
-
 $\omega$
SST model, and the a posteriori (post-injection) TBNN/KCNN-augmented SST model.
$\omega$
SST model, and the a posteriori (post-injection) TBNN/KCNN-augmented SST model.
As seen in figure 23, the primary feature of this flow is a recirculation zone which appears immediately after the left hill. The recirculation zone is most clearly visualised by examining the
 $U_1$
fields. The
$U_1$
fields. The
 $k$
-
$k$
-
 $\omega$
SST model over-predicts the size of this recirculation zone. After correction via injecting the TBNN/KCNN predictions, the recirculation zone size closely matches the DNS data. In the
$\omega$
SST model over-predicts the size of this recirculation zone. After correction via injecting the TBNN/KCNN predictions, the recirculation zone size closely matches the DNS data. In the
 $U_2$
field, a region with
$U_2$
field, a region with
 $U_2\lt 0$
is seen immediately above this recirculation region. The baseline
$U_2\lt 0$
is seen immediately above this recirculation region. The baseline
 $k$
-
$k$
-
 $\omega$
SST model under-predicts the downward velocity here, leading to delayed reattachment, and a longer recirculation zone. After correction, the magnitude of
$\omega$
SST model under-predicts the downward velocity here, leading to delayed reattachment, and a longer recirculation zone. After correction, the magnitude of
 $U_2$
in this shear layer more closely matches the DNS data. On the right hill, the upward acceleration of the flow under the favourable pressure gradient is also under-predicted by the
$U_2$
in this shear layer more closely matches the DNS data. On the right hill, the upward acceleration of the flow under the favourable pressure gradient is also under-predicted by the
 $k$
-
$k$
-
 $\omega$
SST. Here, the injected
$\omega$
SST. Here, the injected
 $\tilde a_{\textit{ij}}$
is able to better capture the strength of this upward acceleration.
$\tilde a_{\textit{ij}}$
is able to better capture the strength of this upward acceleration.
Figure 24 more closely examines the improvements offered by augmenting the
 $k$
-
$k$
-
 $\omega$
SST model via the TBNN/KCNN. It can be seen that the overall magnitudes of the errors in
$\omega$
SST model via the TBNN/KCNN. It can be seen that the overall magnitudes of the errors in
 $U_1$
and
$U_1$
and
 $U_2$
are significantly reduced after injecting the TBNN/KCNN model predictions. In particular, error in
$U_2$
are significantly reduced after injecting the TBNN/KCNN model predictions. In particular, error in
 $U_1$
is reduced in the reattachment region along the bottom wall, and the bulk flow above this region. Error in
$U_1$
is reduced in the reattachment region along the bottom wall, and the bulk flow above this region. Error in
 $U_2$
is reduced in the previously identified shear layer above the recirculation region, and the accelerating region before the outlet.
$U_2$
is reduced in the previously identified shear layer above the recirculation region, and the accelerating region before the outlet.
2.2. Impact of realisability-informed training
To determine the impact that including a realisability-informed penalty has on the training process, the closure term predictions for the three test cases were examined in greater detail. Two loss functions were used: one with
 $\alpha =0$
(representing no realisability penalty), and one with
$\alpha =0$
(representing no realisability penalty), and one with
 $\alpha =10^2$
(representing an exaggerated realisability penalty term in the loss function). The objective of this test was to determine whether including the realisability penalty during training promotes better generalisation of the closure mapping to unseen flow variations.
$\alpha =10^2$
(representing an exaggerated realisability penalty term in the loss function). The objective of this test was to determine whether including the realisability penalty during training promotes better generalisation of the closure mapping to unseen flow variations.
All TBNN hyperparameters were fixed to those given in table 2. Since the realisability-informed training procedure only applies to the TBNN, a perfect prediction of
 $k$
via the KCNN was assumed for calculating error in
$k$
via the KCNN was assumed for calculating error in
 $\tilde a_{\textit{ij}}$
.
$\tilde a_{\textit{ij}}$
.
Table 3 compares the MSE in
 $\tilde a_{\textit{ij}}$
on the hold-out test set, with and without realisability penalties being used in training. It should be noted that similar to the a priori tests in § 2, the linear component used when visualising
$\tilde a_{\textit{ij}}$
on the hold-out test set, with and without realisability penalties being used in training. It should be noted that similar to the a priori tests in § 2, the linear component used when visualising
 $b_{\textit{ij}}$
comes from
$b_{\textit{ij}}$
comes from
 $S^\theta _{\textit{ij}}$
, as is the configuration when training the TBNN. This linear component is the one used when training the TBNN, and therefore its use here provides the most fair assessment of how the proposed loss function promotes more physically realisable results.
$S^\theta _{\textit{ij}}$
, as is the configuration when training the TBNN. This linear component is the one used when training the TBNN, and therefore its use here provides the most fair assessment of how the proposed loss function promotes more physically realisable results.
Table 3. Comparison of mean squared error and number of non-realisable predictions when training with and without a realisability-informed loss function.

As seen in table 3, the realisability-informed loss function significantly reduces realisability violations on unseen flow variations. Even on hold-out test cases, the model is able to predict
 $b_{\textit{ij}}$
without any realisability violations. In some cases, a small tradeoff in
$b_{\textit{ij}}$
without any realisability violations. In some cases, a small tradeoff in
 $a_{\textit{ij}}$
occurs – this tradeoff is expected, as for some difficult points the realisability-informed loss function involves a tradeoff between error and realisability. However, in all cases, realisability-informed training also reduces the error in
$a_{\textit{ij}}$
occurs – this tradeoff is expected, as for some difficult points the realisability-informed loss function involves a tradeoff between error and realisability. However, in all cases, realisability-informed training also reduces the error in
 $b_{\textit{ij}}$
. This error reduction in
$b_{\textit{ij}}$
. This error reduction in
 $b_{\textit{ij}}$
is expected, since all
$b_{\textit{ij}}$
is expected, since all
 $b_{\textit{ij}}$
reference data are realisable. In the case of predicting
$b_{\textit{ij}}$
reference data are realisable. In the case of predicting
 $b_{\textit{ij}}$
accurately, the gradients of the realisability penalty
$b_{\textit{ij}}$
accurately, the gradients of the realisability penalty
 $\mathcal{R}(b_{\textit{ij}})$
further push the predictions towards an accurate prediction of
$\mathcal{R}(b_{\textit{ij}})$
further push the predictions towards an accurate prediction of
 $b_{\textit{ij}}$
, compared with a purely MSE gradient.
$b_{\textit{ij}}$
, compared with a purely MSE gradient.
To further visualise the realisability of the TBNN predictions, the barycentric map of Banerjee et al. (Reference Banerjee, Krahl, Durst and Zenger2007) was used. In the barycentric map, the eigenvalues of a given
 $b_{\textit{ij}}$
are mapped into a triangle, the bounds of which represent the limiting realisable behaviours of turbulent fluctuations. This triangle is useful to spatially visualise realisability violations, and types of turbulent flow physics predicted by the baseline turbulence model, the ML-augmented turbulence model and DNS. Further details on the construction of this mapping are given in Banerjee et al. (Reference Banerjee, Krahl, Durst and Zenger2007) and Emory & Iaccarino (Reference Emory and Iaccarino2014).
$b_{\textit{ij}}$
are mapped into a triangle, the bounds of which represent the limiting realisable behaviours of turbulent fluctuations. This triangle is useful to spatially visualise realisability violations, and types of turbulent flow physics predicted by the baseline turbulence model, the ML-augmented turbulence model and DNS. Further details on the construction of this mapping are given in Banerjee et al. (Reference Banerjee, Krahl, Durst and Zenger2007) and Emory & Iaccarino (Reference Emory and Iaccarino2014).
Figure 25 compares the realisability of the predictions made by a model trained on only a MSE loss function with a model trained on the realisability-informed loss function for the three flows in the present study. All predictions are for the hold-out test set for each flow, representing a generalisation test. The goal of the realisability-informed loss function is to encode a preference for realisable predictions into the model when generalising outside of the training dataset. Figure 25 shows a clear improvement in the realisability of the TBNN predictions. This visualisation supports the results in table 3 in that a realisability-informed model has significantly lower realisability violations when predicting the anisotropy tensor on a new flow. Nearly all of the predictions from the realisability-informed model fall within the realisable boundaries, while the model trained only on MSE predicts several realisability-violating results when generalising to new cases of complex flows such as the duct and periodic hill cases. Also, the violations of physical realisability for the realisability-informed model (when they do occur) are not as severe (as measured from the magnitude of deviation outside the barycentric map) as those obtained from only a MSE loss function.
Figure 25 also shows that for all flows in the present study, the original
 $k$
-
$k$
-
 $\omega$
SST model predicts plane-strain turbulence. All flows in the present study have a strain rate tensor which results in at least one zero eigenvalue of
$\omega$
SST model predicts plane-strain turbulence. All flows in the present study have a strain rate tensor which results in at least one zero eigenvalue of
 $b_{\textit{ij}}$
, for the linear eddy viscosity approximation (
$b_{\textit{ij}}$
, for the linear eddy viscosity approximation (
 $b_{\textit{ij}} = -\nu _t/k S_{\textit{ij}}$
), and therefore plane-strain turbulence is predicted for all flows by the
$b_{\textit{ij}} = -\nu _t/k S_{\textit{ij}}$
), and therefore plane-strain turbulence is predicted for all flows by the
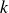 $k$
-
$k$
-
 $\omega$
SST model.
$\omega$
SST model.

Figure 25. Projection of the predicted
 $b_{\textit{ij}}$
from the DNS reference data (a,
e,i), the
$b_{\textit{ij}}$
from the DNS reference data (a,
e,i), the
 $k$
-
$k$
-
 $\omega$
SST model (b, f, j) and the TBNN/KCNN with (d,h,l) and without (c,g,k) realisability-informed learning onto the barycentric triangle. Panels (a)–(d) show the flat plate data, (e)–(h) show the square duct data and (i)–(l) show the periodic hill data. Points outside the triangle are not realisable.
$\omega$
SST model (b, f, j) and the TBNN/KCNN with (d,h,l) and without (c,g,k) realisability-informed learning onto the barycentric triangle. Panels (a)–(d) show the flat plate data, (e)–(h) show the square duct data and (i)–(l) show the periodic hill data. Points outside the triangle are not realisable.
As discussed in § 1.3, realisability-informed learning function does not guarantee a fully realisable prediction. Rather, realisability-informed learning encodes a preference for realisable predictions into the model predictions. This avoids the need for ad hoc post-processing of the predicted anisotropy tensor, while also encoding a physics-based (learning) bias into the TBNN. Strict realisability can be further enforced by post-processing any non-realisable predictions by the TBNN, as the anisotropy tensor can still be accessed and assessed for realisability in the proposed framework (albeit, with an evolving linear component).
An important distinction between the dimensional and non-dimensional anisotropy tensor can also be drawn from the results in this section. In turbulence modelling, it is often the non-dimensional anisotropy tensor
 $b_{\textit{ij}}$
that is thought to be of interest – indeed, it is possible to non-dimensionalise the closure problem (e.g. the generalised eddy viscosity model proposed by Pope (Reference Pope1975)). However, in the present study, we show that even with physically realisable DNS data, dimensionalising the anisotropy tensor via
$b_{\textit{ij}}$
that is thought to be of interest – indeed, it is possible to non-dimensionalise the closure problem (e.g. the generalised eddy viscosity model proposed by Pope (Reference Pope1975)). However, in the present study, we show that even with physically realisable DNS data, dimensionalising the anisotropy tensor via
 $a_{\textit{ij}}=2kb_{\textit{ij}}$
provides a distinct learning target and loss landscape. The realisability-informed loss function does not, in principle, compete against a simple error-based loss function in terms of predicting the non-dimensional
$a_{\textit{ij}}=2kb_{\textit{ij}}$
provides a distinct learning target and loss landscape. The realisability-informed loss function does not, in principle, compete against a simple error-based loss function in terms of predicting the non-dimensional
 $b_{\textit{ij}}$
– non-realisable predictions will also have high error. However, setting the dimensional anisotropy tensor as the target creates a tradeoff between these two objectives, as demonstrated by the results in table 3. Since predicting the dimensional anisotropy tensor is favourable for the reasons outlined in § 1.3, further investigation is required to determine the exact source of this tradeoff. This future research area is particularly relevant for learning anisotropy mappings from data, a major area of focus for improving RANS via ML.
$b_{\textit{ij}}$
– non-realisable predictions will also have high error. However, setting the dimensional anisotropy tensor as the target creates a tradeoff between these two objectives, as demonstrated by the results in table 3. Since predicting the dimensional anisotropy tensor is favourable for the reasons outlined in § 1.3, further investigation is required to determine the exact source of this tradeoff. This future research area is particularly relevant for learning anisotropy mappings from data, a major area of focus for improving RANS via ML.
3. Conclusion
The objectives of this study were to propose a physics-informed loss function for training TBNN anisotropy mappings, a new TBNN architecture and a new injection framework that accommodates implicit treatment of the linear anisotropy component within a TBNN-type architecture. This framework addresses an issue related to the stability of injected TBNN predictions, an issue that has been reported by Kaandorp & Dwight (Reference Kaandorp and Dwight2020), and consistent with our own experience. This framework also addresses the issue of realisability within the context of predicting the anisotropy tensor from RANS input features.
The results here indicate that the proposed model architecture generalises well to new flow configurations, and the predicted anisotropy tensor can be injected in a highly stable manner. During the injection procedure in the present investigation, the Computational Fluid Dynamics solver remained stable, even when testing erratic model predictions. While this finding corroborates findings from others that frameworks which leverage implicit treatment of the linear anisotropy component via an eddy viscosity are numerically stable (Wu et al. Reference Wu, Sun, Laizet and Xiao2019b
; Brener et al. Reference Brener, Cruz, Thompson and Anjos2021; Liu et al. Reference Liu, Fang, Rolfo, Moulinec and Emerson2021), a novelty in the present investigation is the avoidance of using an optimal eddy viscosity. With the proposed decomposition of
 $a_{\textit{ij}}$
(§ 1.1), a simpler (and more straightforward) baseline
$a_{\textit{ij}}$
(§ 1.1), a simpler (and more straightforward) baseline
 $k$
-
$k$
-
 $\omega$
SST eddy viscosity is used. The core modification that allows a well-conditioned solution in this case is the use of
$\omega$
SST eddy viscosity is used. The core modification that allows a well-conditioned solution in this case is the use of
 $S^\theta _{\textit{ij}}$
within
$S^\theta _{\textit{ij}}$
within
 $\hat {T}^{(1)}_{\textit{ij}}$
in the TBNN training process. As a result, all corrections induced by the TBNN are contained in an explicit term in the momentum equation. Future work includes investigating how new flow generalisation can be improved by a blending factor that multiplies this explicit term, thereby allowing the correction to be turned off. For example, a statistics-based scalar or a separate machine learning model could be used to predict a blending factor. This blending factor could reduce or eliminate corrections when a test data point departs significantly (is out of distribution) from the training dataset, and erroneous predictions are likely.
$\hat {T}^{(1)}_{\textit{ij}}$
in the TBNN training process. As a result, all corrections induced by the TBNN are contained in an explicit term in the momentum equation. Future work includes investigating how new flow generalisation can be improved by a blending factor that multiplies this explicit term, thereby allowing the correction to be turned off. For example, a statistics-based scalar or a separate machine learning model could be used to predict a blending factor. This blending factor could reduce or eliminate corrections when a test data point departs significantly (is out of distribution) from the training dataset, and erroneous predictions are likely.
While the realisability-informed loss function does not strictly guarantee physical realisability of the predictions, the results in § 2.2 indicate that the model retains a realisability bias when generalising. The realisability-informed loss function is not only applicable to the framework and architecture proposed in this study – it could be used anytime an anisotropy mapping is generated via machine learning. The use of the realisability-informed loss function in the present investigation promoted better realisability of predictions by a TBNN, but we fully expect the bias induced by this loss function to also be beneficial for tensor basis random forests (e.g. Kaandorp & Dwight (Reference Kaandorp and Dwight2020)), or non-tensor basis frameworks (e.g. Wu et al. (Reference Wu, Xiao and Paterson2018)). Since high-quality DNS anisotropy tensor data are realisable, the realisability penalty can be viewed as an additional boost to the loss function gradient towards the true value, when a non-realisable prediction is made. Future work will investigate how the realisability-informed loss function performs with training data generated by LES, which are not guaranteed to be realisable.
The KCNN used in the proposed framework to correct
 $k$
could also be replaced by coupling the
$k$
could also be replaced by coupling the
 $k$
equation to the momentum equation, as exists in the original turbulence model, and the TBNN approach originally proposed by Ling et al. (Reference Ling, Kurzawski and Templeton2016). At training time,
$k$
equation to the momentum equation, as exists in the original turbulence model, and the TBNN approach originally proposed by Ling et al. (Reference Ling, Kurzawski and Templeton2016). At training time,
 $k^\theta$
is used to dimensionalise
$k^\theta$
is used to dimensionalise
 $b_{\textit{ij}}$
in the present study, since
$b_{\textit{ij}}$
in the present study, since
 $k$
is corrected via the KCNN. This direct correction produced satisfactory results in the present work, but it is possible that generalisation could be further enhanced by the re-coupling the
$k$
is corrected via the KCNN. This direct correction produced satisfactory results in the present work, but it is possible that generalisation could be further enhanced by the re-coupling the
 $k$
equation with an updated closure term. This enhanced generalisation would result from the fact that a physics-based coupled equation system is used to correct
$k$
equation with an updated closure term. This enhanced generalisation would result from the fact that a physics-based coupled equation system is used to correct
 $k$
, rather than a simple multiplicative corrector (the KCNN in the present investigation). However, this coupling of an additional partial differential equation introduces the possibility for instability, an issue which is common in machine learning anisotropy modelling. Future work will investigate the merits of this route.
$k$
, rather than a simple multiplicative corrector (the KCNN in the present investigation). However, this coupling of an additional partial differential equation introduces the possibility for instability, an issue which is common in machine learning anisotropy modelling. Future work will investigate the merits of this route.
Ultimately, this investigation demonstrates that with sufficient modifications, TBNN-type anisotropy mappings can be injected in a stable and well-conditioned manner. Further, with appropriate physics-based loss function penalties, the mapping can be sensitised to more physically informative targets than MSE. Moreover, we provided a preliminary investigation of the utility of KANs for turbulence closure modelling. While TBKAN did not outperform TBNN in this context, they nevertheless demonstrated the potential for capturing the complex relationships in the anisotropy tensor (at least in the flat plate case), suggesting that future research work should be conducted on the use of KANs for turbulent closure modelling applications. While industrial use of machine learning-based anisotropy mappings is currently not widespread, the continual development of techniques which increase the practicality of training and injecting model predictions will help accelerate more widespread use. Machine learning-augmented turbulence closure modelling is an aid that the turbulence modelling community can use to help bridge the current computational gap between RANS and widespread use of LES (Witherden & Jameson Reference Witherden and Jameson2017).
Acknowledgements
We sincerely thank the anonymous reviewers for their careful review and helpful suggestions for the manuscript.
Funding
This work was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) Postgraduate Scholarship program. Computational resources for this work were supported by the Tyler Lewis Clean Energy Research Foundation.
Declaration of interests
The authors report no conflict of interest.
Data availability statement
All code and data that support the results of this study are publicly available. The code can be found at https://github.com/rmcconke/tbnn. The dataset used in this work is available at https://doi.org/10.34740/kaggle/dsv/2637500.
Author contributions
R.M.: conceptualisation, methodology, software, validation, investigation, data curation, writing (original draft, review and editing), visualisation. N.K. (KAN related work): conceptualisation, methodology, software, validation, investigation, writing (original draft, review and editing), visualisation. E.Y.: conceptualisation, methodology writing (review and editing), supervision, project administration, funding acquisition. F.S.L.: conceptualisation, methodology, writing (review and editing), supervision, project administration, funding acquisition.
Appendix A. Integrity basis input features
Wu et al.’s integrity basis is derived from four gradient tensors:
 $\hat {S}$
,
$\hat {S}$
,
 $\hat {R}$
,
$\hat {R}$
,
 $\hat {A}_p$
and
$\hat {A}_p$
and
 $\hat {A}_k$
(Wu et al. Reference Wu, Xiao and Paterson2018). These tensors are calculated as follows:
$\hat {A}_k$
(Wu et al. Reference Wu, Xiao and Paterson2018). These tensors are calculated as follows:
 \begin{align} \hat {S}_{\textit{ij}}&= C_{S} \frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} + \frac {\partial U_{\!j}}{\partial x_i}\right )\! , \end{align}
\begin{align} \hat {S}_{\textit{ij}}&= C_{S} \frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} + \frac {\partial U_{\!j}}{\partial x_i}\right )\! , \end{align}
 \begin{align} \hat {R}_{\textit{ij}} &= C_{R}\frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} - \frac {\partial U_{\!j}}{\partial x_i}\right )\! , \end{align}
\begin{align} \hat {R}_{\textit{ij}} &= C_{R}\frac {1}{2}\left (\frac {\partial U_i}{\partial x_j} - \frac {\partial U_{\!j}}{\partial x_i}\right )\! , \end{align}
 \begin{align} \hat {A}_p &= C_{A_p} \epsilon _{\textit{ijl}} \frac {\partial p}{\partial x_l} , \end{align}
\begin{align} \hat {A}_p &= C_{A_p} \epsilon _{\textit{ijl}} \frac {\partial p}{\partial x_l} , \end{align}
 \begin{align} \hat {A}_k&= C_{A_k}\epsilon _{\textit{ijl}} \frac {\partial k}{\partial x_l} , \\[7pt] \nonumber \end{align}
\begin{align} \hat {A}_k&= C_{A_k}\epsilon _{\textit{ijl}} \frac {\partial k}{\partial x_l} , \\[7pt] \nonumber \end{align}
where
 $C_S$
,
$C_S$
,
 $C_R$
,
$C_R$
,
 $C_{A_p}$
and
$C_{A_p}$
and
 $C_{A_k}$
are scalars which non-dimensionalise their corresponding gradient tensors, and
$C_{A_k}$
are scalars which non-dimensionalise their corresponding gradient tensors, and
 $\epsilon _{\textit{ijl}}$
is the Levi-Civita symbol. For example, Ling et al. (Reference Ling, Kurzawski and Templeton2016) chose
$\epsilon _{\textit{ijl}}$
is the Levi-Civita symbol. For example, Ling et al. (Reference Ling, Kurzawski and Templeton2016) chose
 $C_{S}=C_{R}=k/\varepsilon$
, so that
$C_{S}=C_{R}=k/\varepsilon$
, so that
 $\hat {S}$
is dimensionless.
$\hat {S}$
is dimensionless.
Without loss of generality, the scalars
 $p$
and
$p$
and
 $k$
in the above can be swapped out for other scalars, such as
$k$
in the above can be swapped out for other scalars, such as
 $\varepsilon$
, or
$\varepsilon$
, or
 $\omega$
, thereby replacing
$\omega$
, thereby replacing
 $\hat {A}_{p,ij}$
and
$\hat {A}_{p,ij}$
and
 $\hat {A}_{k,ij}$
with
$\hat {A}_{k,ij}$
with
 $\hat {C_{\textit{ij}}}$
and
$\hat {C_{\textit{ij}}}$
and
 $\hat {D}_{\textit{ij}}$
$\hat {D}_{\textit{ij}}$
 \begin{align} \hat {C}_{\textit{ij}} &= C_{C} \epsilon _{\textit{ijl}} \frac {\partial s_1}{\partial x_l} , \end{align}
\begin{align} \hat {C}_{\textit{ij}} &= C_{C} \epsilon _{\textit{ijl}} \frac {\partial s_1}{\partial x_l} , \end{align}
 \begin{align} \hat {D}_{\textit{ij}}&= C_{D}\epsilon _{\textit{ijl}} \frac {\partial s_2}{\partial x_l} , \end{align}
\begin{align} \hat {D}_{\textit{ij}}&= C_{D}\epsilon _{\textit{ijl}} \frac {\partial s_2}{\partial x_l} , \end{align}
where
 $s_1$
and
$s_1$
and
 $s_2$
are two scalar fields. For example, in the present study,
$s_2$
are two scalar fields. For example, in the present study,
 $s_1=\omega$
, and
$s_1=\omega$
, and
 $s_2=k$
. In 3-D Cartesian coordinates, the strain rate, rotation rate and antisymmetric tensors associated with the two scalar gradients are
$s_2=k$
. In 3-D Cartesian coordinates, the strain rate, rotation rate and antisymmetric tensors associated with the two scalar gradients are
 \begin{align} \hat {S}_{\textit{ij}} &=\frac {C_S}{2}\begin{bmatrix} 2\dfrac {\strut \partial U_1}{\strut \partial x_1} & \dfrac {\strut \partial U_1}{\strut \partial x_2} + \dfrac {\strut \partial U_2}{\strut \partial x_1} & \dfrac {\strut \partial U_1}{\strut \partial x_3} + \dfrac {\strut \partial U_3}{\strut \partial x_1}\\[8pt] \dfrac {\strut \partial U_2}{\strut \partial x_1}+\dfrac {\strut \partial U_1}{\strut \partial x_2} & 2\dfrac {\strut \partial U_2}{\strut \partial x_2} & \dfrac {\strut \partial U_2}{\strut \partial x_3} + \dfrac {\strut \partial U_3}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial U_3}{\strut \partial x_1}+\dfrac {\strut \partial U_1}{\strut \partial x_3} & \dfrac {\strut \partial U_3}{\strut \partial x_2} +\dfrac {\strut \partial U_2}{\strut \partial x_3} & 2\dfrac {\strut \partial U_3}{\strut \partial x_3} \end{bmatrix}\! , \end{align}
\begin{align} \hat {S}_{\textit{ij}} &=\frac {C_S}{2}\begin{bmatrix} 2\dfrac {\strut \partial U_1}{\strut \partial x_1} & \dfrac {\strut \partial U_1}{\strut \partial x_2} + \dfrac {\strut \partial U_2}{\strut \partial x_1} & \dfrac {\strut \partial U_1}{\strut \partial x_3} + \dfrac {\strut \partial U_3}{\strut \partial x_1}\\[8pt] \dfrac {\strut \partial U_2}{\strut \partial x_1}+\dfrac {\strut \partial U_1}{\strut \partial x_2} & 2\dfrac {\strut \partial U_2}{\strut \partial x_2} & \dfrac {\strut \partial U_2}{\strut \partial x_3} + \dfrac {\strut \partial U_3}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial U_3}{\strut \partial x_1}+\dfrac {\strut \partial U_1}{\strut \partial x_3} & \dfrac {\strut \partial U_3}{\strut \partial x_2} +\dfrac {\strut \partial U_2}{\strut \partial x_3} & 2\dfrac {\strut \partial U_3}{\strut \partial x_3} \end{bmatrix}\! , \end{align}
 \begin{align} \hat {R}_{\textit{ij}}&= \frac {C_R}{2}\begin{bmatrix} 0 & \dfrac {\strut \partial U_1}{\strut \partial x_2} - \dfrac {\strut \partial U_2}{\strut \partial x_1} & \dfrac {\strut \partial U_1}{\strut \partial x_3} - \dfrac {\strut \partial U_3}{\strut \partial x_1}\\[8pt] \dfrac {\strut \partial U_2}{\strut \partial x_1}-\dfrac {\strut \partial U_1}{\strut \partial x_2} & 0 & \dfrac {\strut \partial U_2}{\strut \partial x_3} - \dfrac {\strut \partial U_3}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial U_3}{\strut \partial x_1}-\dfrac {\strut \partial U_1}{\strut \partial x_3} & \dfrac {\strut \partial U_3}{\strut \partial x_2} -\dfrac {\strut \partial U_2}{\strut \partial x_3} & 0 \end{bmatrix}\! , \end{align}
\begin{align} \hat {R}_{\textit{ij}}&= \frac {C_R}{2}\begin{bmatrix} 0 & \dfrac {\strut \partial U_1}{\strut \partial x_2} - \dfrac {\strut \partial U_2}{\strut \partial x_1} & \dfrac {\strut \partial U_1}{\strut \partial x_3} - \dfrac {\strut \partial U_3}{\strut \partial x_1}\\[8pt] \dfrac {\strut \partial U_2}{\strut \partial x_1}-\dfrac {\strut \partial U_1}{\strut \partial x_2} & 0 & \dfrac {\strut \partial U_2}{\strut \partial x_3} - \dfrac {\strut \partial U_3}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial U_3}{\strut \partial x_1}-\dfrac {\strut \partial U_1}{\strut \partial x_3} & \dfrac {\strut \partial U_3}{\strut \partial x_2} -\dfrac {\strut \partial U_2}{\strut \partial x_3} & 0 \end{bmatrix}\! , \end{align}
 \begin{align} \hat {C}_{\textit{ij}} &= C_C \begin{bmatrix} 0 & -\dfrac {\strut \partial s_1}{\strut \partial x_3} & \dfrac {\strut \partial s_1}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial s_1}{\strut \partial x_3} & 0 & -\dfrac {\strut \partial s_1}{\strut \partial x_1}\\[8pt] -\dfrac {\partial s_1}{\strut \partial x_2} & \dfrac {\strut \partial s_1}{\strut \partial x_1} & 0 \end{bmatrix}\! , \end{align}
\begin{align} \hat {C}_{\textit{ij}} &= C_C \begin{bmatrix} 0 & -\dfrac {\strut \partial s_1}{\strut \partial x_3} & \dfrac {\strut \partial s_1}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial s_1}{\strut \partial x_3} & 0 & -\dfrac {\strut \partial s_1}{\strut \partial x_1}\\[8pt] -\dfrac {\partial s_1}{\strut \partial x_2} & \dfrac {\strut \partial s_1}{\strut \partial x_1} & 0 \end{bmatrix}\! , \end{align}
 \begin{align} \hat {D}_{\textit{ij}} &= C_D \begin{bmatrix} 0 & -\dfrac {\strut \partial s_2}{\strut \partial x_3} & \dfrac {\strut \partial s_2}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial s_2}{\strut \partial x_3} & 0 & -\dfrac {\strut \partial s_2}{\strut \partial x_1}\\[8pt] -\dfrac {\strut \partial s_2}{\strut \partial x_2} & \dfrac {\strut \partial s_2}{\strut \partial x_1} & 0 \end{bmatrix}\!. \end{align}
\begin{align} \hat {D}_{\textit{ij}} &= C_D \begin{bmatrix} 0 & -\dfrac {\strut \partial s_2}{\strut \partial x_3} & \dfrac {\strut \partial s_2}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial s_2}{\strut \partial x_3} & 0 & -\dfrac {\strut \partial s_2}{\strut \partial x_1}\\[8pt] -\dfrac {\strut \partial s_2}{\strut \partial x_2} & \dfrac {\strut \partial s_2}{\strut \partial x_1} & 0 \end{bmatrix}\!. \end{align}
Under some conditions, input features derived from invariants of the minimal integrity basis derived by Wu et al. (Reference Wu, Xiao and Paterson2018) can vanish. These conditions occur when there are zero gradients in the flow, as all tensors in Wu’s et al.’s integrity basis are derived from gradient-based tensors.
Here, we consider two cases.
-
(i) Two-dimensional flow.
The zero pressure gradient boundary layer and periodic hill cases in the present study fall into this category. With the coordinate system defined as it was in § 2.1.5, the velocity vector is
$U_{\!j} = (U_1, U_2, 0)$
, and the gradient tensors take the following form in 3-D space:(A11)
\begin{align} \hat {S}_{\textit{ij}} &=\frac {C_S}{2}\begin{bmatrix} 2\dfrac {\strut \partial U_1}{\strut \partial x_1} & \dfrac {\strut \partial U_1}{\strut \partial x_2} + \dfrac {\strut \partial U_2}{\strut \partial x_1} & 0\\[8pt] \dfrac {\strut \partial U_2}{\strut \partial x_1}+\dfrac {\strut \partial U_1}{\strut \partial x_2} & 2\dfrac {\strut \partial U_2}{\strut \partial x_2} & 0\\[8pt] 0 & 0 & 0 \end{bmatrix}\! , \end{align}
(A12)
\begin{align} \hat {R}_{\textit{ij}}&= \frac {C_R}{2}\begin{bmatrix} 0 & \dfrac {\strut \partial U_1}{\strut \partial x_2} - \dfrac {\strut \partial U_2}{\strut \partial x_1} & 0\\[8pt] \dfrac {\strut \partial U_2}{\strut \partial x_1}-\dfrac {\strut \partial U_1}{\strut \partial x_2} & 0 & 0\\[8pt] 0 & 0 & 0 \end{bmatrix}\! , \end{align}
(A13)
\begin{align} \hat {C}_{\textit{ij}} &= C_C \begin{bmatrix} 0 & 0 & \dfrac {\strut \partial s_1}{\strut \partial x_2}\\[8pt] 0 & 0 & -\dfrac {\strut \partial s_1}{\strut \partial x_1}\\[8pt] -\dfrac {\partial s_1}{\strut \partial x_2} & \dfrac {\strut \partial s_1}{\strut \partial x_1} & 0 \end{bmatrix}\! , \end{align}
(A14)
\begin{align} \hat {D}_{\textit{ij}} &= C_D \begin{bmatrix} 0 & 0 & \dfrac {\strut \partial s_2}{\strut \partial x_2}\\[8pt] 0 & 0 & -\dfrac {\strut \partial s_2}{\strut \partial x_1}\\[8pt] -\dfrac {\strut \partial s_2}{\strut \partial x_2} & \dfrac {\strut \partial s_2}{\strut \partial x_1} & 0 \ \end{bmatrix}\!. \\[9pt] \nonumber \end{align}
-
(ii) Three-dimensional flow with zero gradients in one direction.
The square duct case in the present study falls into this category. With the coordinate system defined as it was in § 2.1.3, the velocity vector is
$U_{\!j} = (U_1, U_2, U_3)$
. All gradients in the
$x_1$
direction are zero:
$\partial ()/\partial x_1 = 0$
. In this case, the gradient tensors take the following form in 3-D space:(A15)
\begin{align} \hat {S}_{\textit{ij}} &=\frac {C_S}{2}\begin{bmatrix} 0 & \dfrac {\strut \partial U_1}{\strut \partial x_2} & \dfrac {\strut \partial U_1}{\strut \partial x_3} \\[8pt] \dfrac {\strut \partial U_1}{\strut \partial x_2} & 2\dfrac {\strut \partial U_2}{\strut \partial x_2} & \dfrac {\strut \partial U_2}{\strut \partial x_3} + \dfrac {\strut \partial U_3}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial U_1}{\strut \partial x_3} & \dfrac {\strut \partial U_3}{\strut \partial x_2} +\dfrac {\strut \partial U_2}{\strut \partial x_3} & 2\dfrac {\strut \partial U_3}{\strut \partial x_3} \end{bmatrix}\! , \end{align}
(A16)
\begin{align} \hat {R}_{\textit{ij}}&= \frac {C_R}{2}\begin{bmatrix} 0 & \dfrac {\strut \partial U_1}{\strut \partial x_2}& \dfrac {\strut \partial U_1}{\strut \partial x_3} \\[8pt] \dfrac {\strut \partial U_1}{\strut \partial x_2} & 0 & \dfrac {\strut \partial U_2}{\strut \partial x_3} - \dfrac {\strut \partial U_3}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial U_1}{\strut \partial x_3} & \dfrac {\strut \partial U_3}{\strut \partial x_2} -\dfrac {\strut \partial U_2}{\strut \partial x_3} & 0 \end{bmatrix}\! , \end{align}
(A17)
\begin{align} \hat {C}_{\textit{ij}} &= C_C \begin{bmatrix} 0 & -\dfrac {\strut \partial s_1}{\strut \partial x_3} & \dfrac {\strut \partial s_1}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial s_1}{\strut \partial x_3} & 0 & 0\\[8pt] -\dfrac {\partial s_1}{\strut \partial x_2} & 0 & 0 \end{bmatrix}\! , \end{align}
(A18)
\begin{align} \hat {D}_{\textit{ij}} &= C_D \begin{bmatrix} 0 & -\dfrac {\strut \partial s_2}{\strut \partial x_3} & \dfrac {\strut \partial s_2}{\strut \partial x_2}\\[8pt] \dfrac {\strut \partial s_2}{\strut \partial x_3} & 0 & 0\\[8pt] -\dfrac {\strut \partial s_2}{\strut \partial x_2} & 0 & 0 \ \end{bmatrix}\!. \end{align}












Cases (i) and (ii) were analysed using sympy (Meurer et al. Reference Meurer2017) to determine which integrity basis tensor invariants are non-zero, and therefore suitable as potential input features. The first and second invariants of a rank two tensor are scalar functions, defined by
 \begin{align} I_1(A_{\textit{ij}}) &= A_{\textit{ii}}, \end{align}
\begin{align} I_1(A_{\textit{ij}}) &= A_{\textit{ii}}, \end{align}
 \begin{align} I_2(A_{\textit{ij}})&= \frac {1}{2}\left (\left (A_{\textit{ii}}\right )^2 - A_{\textit{ij}}A_{\textit{ji}}\right)\!. \end{align}
\begin{align} I_2(A_{\textit{ij}})&= \frac {1}{2}\left (\left (A_{\textit{ii}}\right )^2 - A_{\textit{ij}}A_{\textit{ji}}\right)\!. \end{align}
The third invariant,
 $I_3=\textbf {det}(A_{\textit{ij}})$
is zero for all of the integrity basis tensors, since they are either antisymmetric, or symmetric and zero trace. Table 4 shows the results of this analysis.
$I_3=\textbf {det}(A_{\textit{ij}})$
is zero for all of the integrity basis tensors, since they are either antisymmetric, or symmetric and zero trace. Table 4 shows the results of this analysis.
Source code which supports the analysis in this appendix and enables further investigation is available on Github (McConkey Reference McConkey2023).
Table 4. Non-zero invariants of the minimal integrity basis tensor formed by
 $\hat {S}_{\textit{ij}}$
,
$\hat {S}_{\textit{ij}}$
,
 $\hat {R}_{\textit{ij}}$
,
$\hat {R}_{\textit{ij}}$
,
 $\hat {C}_{\textit{ij}}$
and
$\hat {C}_{\textit{ij}}$
and
 $\hat {D}_{\textit{ij}}$
.
$\hat {D}_{\textit{ij}}$
.


























































































































 Open access
Open access